From dd23049a5ff775fcd7fa4b1a5dedf5df7921d9c9 Mon Sep 17 00:00:00 2001
From: Wcowin <1135801806@qq.com>
Date: Tue, 3 Jun 2025 20:47:38 +0800
Subject: [PATCH] 25/6/3
---
docs/blog/websitebeauty/MkDocs-AI-Hooks.md | 454 ++++++++++++++++++
.../__pycache__/ai_summary.cpython-311.pyc | Bin 18473 -> 27203 bytes
docs/overrides/hooks/ai_summary.py | 282 +++++++++--
docs/overrides/hooks/test.py | 397 +++++++++++++++
mkdocs.yml | 3 +-
.../608652015d8fccc03a9c1fb96962eb06.json | 6 +
6 files changed, 1093 insertions(+), 49 deletions(-)
create mode 100644 docs/blog/websitebeauty/MkDocs-AI-Hooks.md
create mode 100644 docs/overrides/hooks/test.py
create mode 100644 site/.ai_cache/608652015d8fccc03a9c1fb96962eb06.json
diff --git a/docs/blog/websitebeauty/MkDocs-AI-Hooks.md b/docs/blog/websitebeauty/MkDocs-AI-Hooks.md
new file mode 100644
index 0000000..6929545
--- /dev/null
+++ b/docs/blog/websitebeauty/MkDocs-AI-Hooks.md
@@ -0,0 +1,454 @@
+---
+title: MkDocs文档AI摘要
+tags:
+ - Mkdocs
+status: new
+---
+
+# MkDocs AI Hooks
+
+
+  +
+  +
+  +
+
+
+
+ 中文 | English
+
+
+🚀 **您的MkDocs文档首选智能摘要!**
+这个项目利用MkDocs hooks,为您的技术文档和博客添加AI驱动的摘要生成和智能阅读统计功能。
+
+
+
+网站效果预览:https://wcowin.work/Mkdocs-Wcowin/blog/Mkdocs/mkfirst/
+
+## ✨ 功能特性
+
+### AI智能摘要
+- **自动生成文章摘要**:使用DeepSeek API生成高质量的80-120字摘要
+- **多语言支持**:支持中文、英文等多种语言
+- **多API服务支持**:支持OpenAI、Claude等多种AI服务
+- **智能内容清理**:自动过滤YAML、HTML、代码块等格式内容
+- **备用摘要机制**:API失败时提供基于规则的智能摘要
+- **高效缓存系统**:避免重复API调用,7天智能过期
+- **灵活配置**:支持文件夹级别和页面级别的精确控制
+
+### 智能阅读统计(可选)
+- **精准中文字符统计**:专门优化的中文内容识别
+- **智能代码检测**:识别多种编程语言和命令行代码
+- **阅读时间估算**:基于中文阅读习惯的400字/分钟计算
+- **美观信息展示**:使用MkDocs Material风格的信息框
+
+### 智能化特性
+- **自动语言识别**:支持30+编程语言和标记语言
+- **内容类型检测**:区分代码、配置、命令行等不同内容
+- **缓存优化**:LRU缓存提升性能
+- **错误处理**:完善的异常处理和日志记录
+
+## 📦 安装
+
+### 方法1
+直接下载(推荐)
+在releases页面下载,解压后将以下文件放入您的MkDocs项目的docs/overrides/hooks中:
+https://github.com/Wcowin/mkdocs-ai-hooks/releases
+
+
+或者下载上方hooks目录下的两个Python文件:
+
+- `ai_summary.py`:AI摘要生成器
+
+- `reading_time.py`:阅读时间统计器
+
+```bash
+# 放置到您的项目目录
+mkdir -p docs/overrides/hooks/
+mv ai_summary.py docs/overrides/hooks/
+mv reading_time.py docs/overrides/hooks/
+```
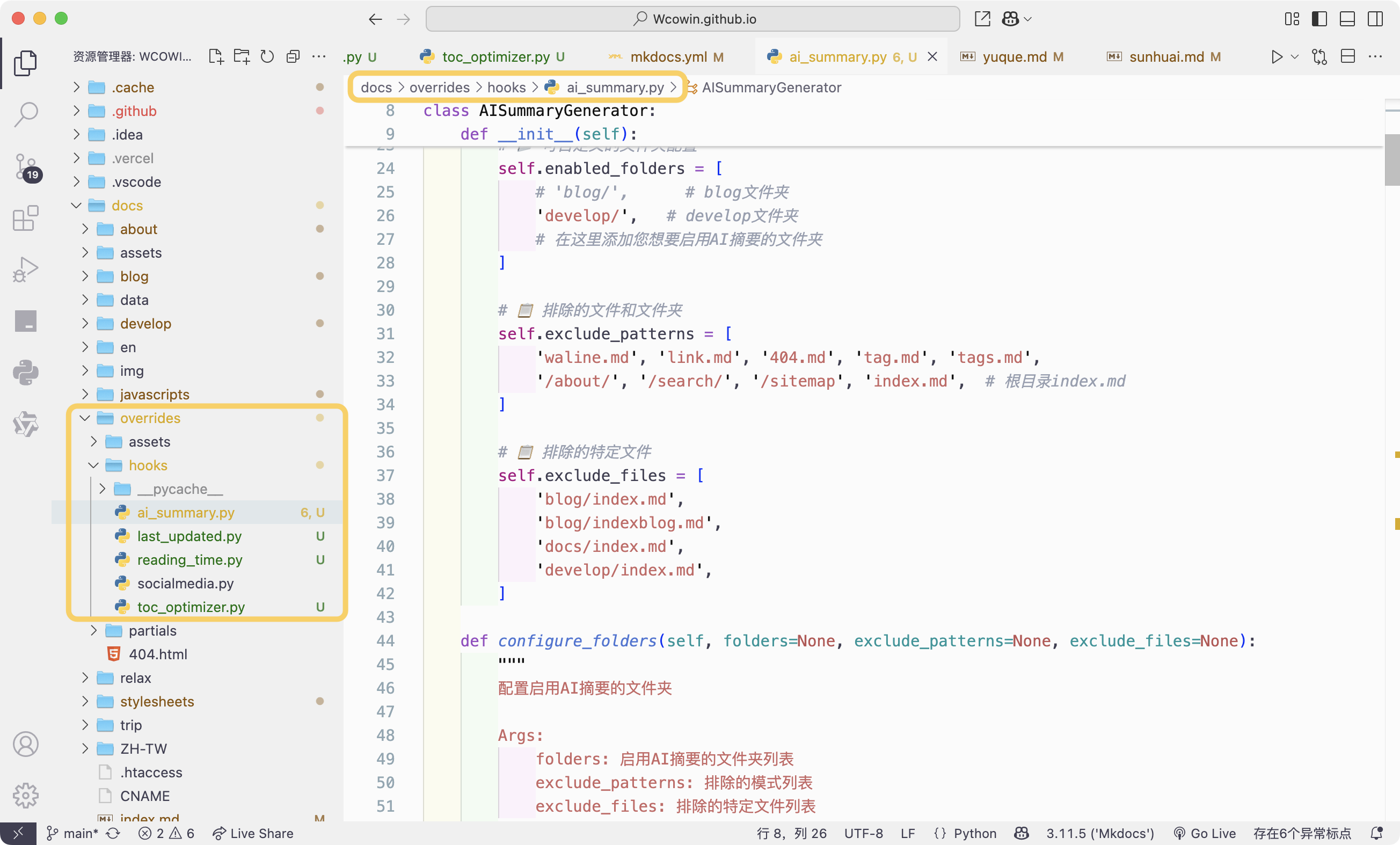
+放置的位置如下:
+
+
+在 `mkdocs.yml` 中theme下添加custom_dir:
+```yaml
+# 可选:Material主题配置
+theme:
+ name: material
+ custom_dir: docs/overrides #一定要有!一定要有!
+ features:
+ - content.code.copy
+ - content.code.select
+```
+
+### 方法2
+
+使用Git克隆
+```bash
+git clone https://github.com/Wcowin/mkdocs-ai-hooks.git
+cd mkdocs-ai-hooks
+pip install -r requirements.txt
+```
+
+### 依赖安装
+```bash
+pip install requirements.txt
+```
+
+## 🚀 快速开始
+
+### 1. 配置MkDocs
+先执行一次`mkdocs build`,生成缓存文件
+```bash
+mkdocs build
+```
+在 `mkdocs.yml` 中添加hooks,theme下添加custom_dir:
+```yaml
+hooks:
+ - docs/overrides/hooks/ai_summary.py # 添加AI摘要hook
+ - docs/overrides/hooks/reading_time.py # 添加统计阅读时间hook
+
+# 可选:Material主题配置
+theme:
+ name: material
+ custom_dir: docs/overrides #一定要有!!
+ features:
+ - content.code.copy
+ - content.code.select
+```
+
+### 2. 在ai_summary.py中配置需要AI摘要的目录
+```python
+# 📂 可自定义的文件夹配置
+self.enabled_folders = [
+ 'blog/', # blog文件夹
+ 'develop/', # develop文件夹
+ # 在这里添加您想要启用AI摘要的文件夹
+]
+
+# 📋 排除的文件和文件夹
+self.exclude_patterns = [
+ 'waline.md', 'link.md', '404.md', 'tag.md', 'tags.md',
+ '/about/', '/search/', '/sitemap', 'index.md', # 根目录index.md
+]
+
+# 📋 排除的特定文件
+self.exclude_files = [
+ 'blog/index.md',
+ 'blog/indexblog.md',
+ 'docs/index.md',
+ 'develop/index.md',
+]
+```
+
+### 3. 在ai_summary.py中设置DeepSeek API(默认是OpenAI)
+```python
+# 在ai_summary.py中修改API配置
+'deepseek': {
+ 'url': 'https://api.deepseek.com/v1/chat/completions',
+ 'model': 'deepseek-chat',
+ 'api_key': os.getenv('DEEPSEEK_API_KEY', 'your-azure-api-key'),
+ 'max_tokens': 150,
+ 'temperature': 0.3
+},
+```
+
+### 4. 运行MkDocs
+第一次运行时,可能需要等待一段时间,因为系统会自动生成摘要。后续运行时,系统会使用缓存数据,加快生成速度。
+```bash
+#依次运行命令
+mkdocs build
+mkdocs serve
+```
+终端输出如下:
+
+
+## 📖 使用指南
+
+### AI摘要配置
+
+#### 文件夹级别控制
+```python
+# 启用特定文件夹
+configure_ai_summary(['blog/', 'docs/', 'tutorials/'])
+
+# 全局启用(除排除项)
+configure_ai_summary([''])
+```
+
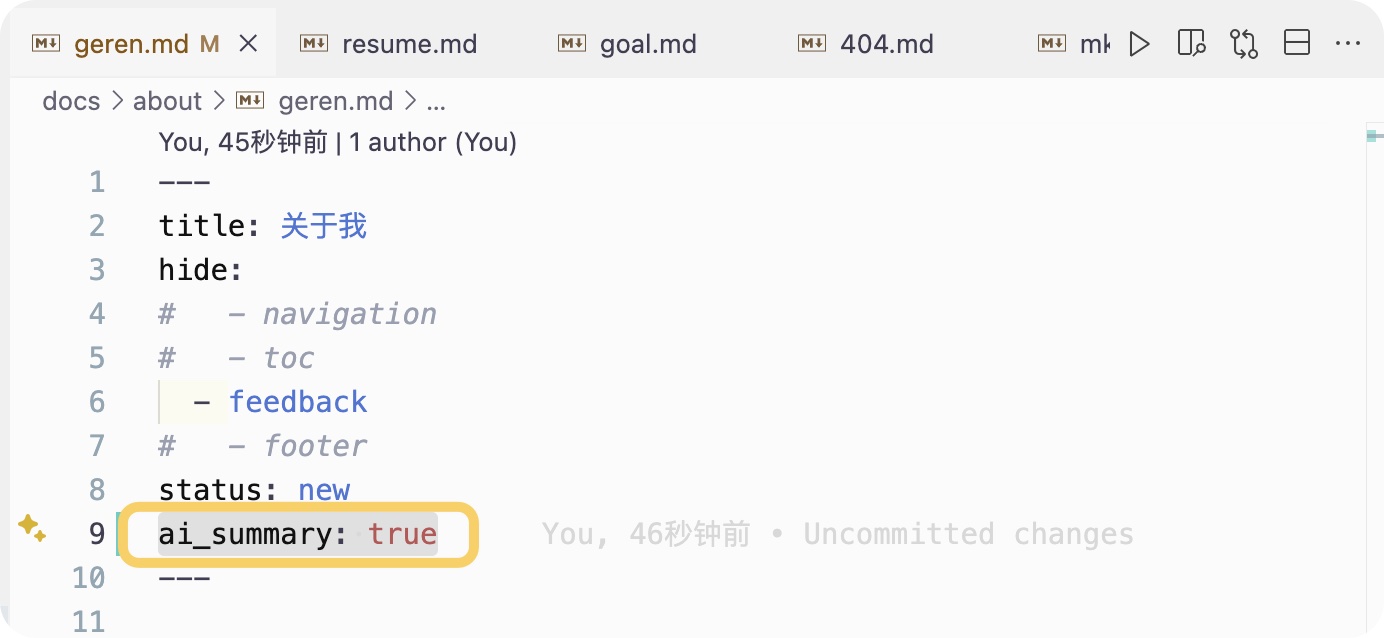
+#### 页面级别控制(推荐)
+在Markdown文件的YAML front matter中:
+
+```yaml
+---
+title: 文章标题
+ai_summary: true # 启用AI摘要
+---
+```
+
+```yaml
+---
+title: 文章标题
+ai_summary: false # 禁用AI摘要
+description: 手动摘要 # 可选
+---
+```
+
+### 阅读时间配置
+
+#### 排除特定页面
+```python
+# 在页面的YAML front matter中
+---
+title: 页面标题
+hide_reading_time: true # 隐藏阅读时间
+---
+```
+
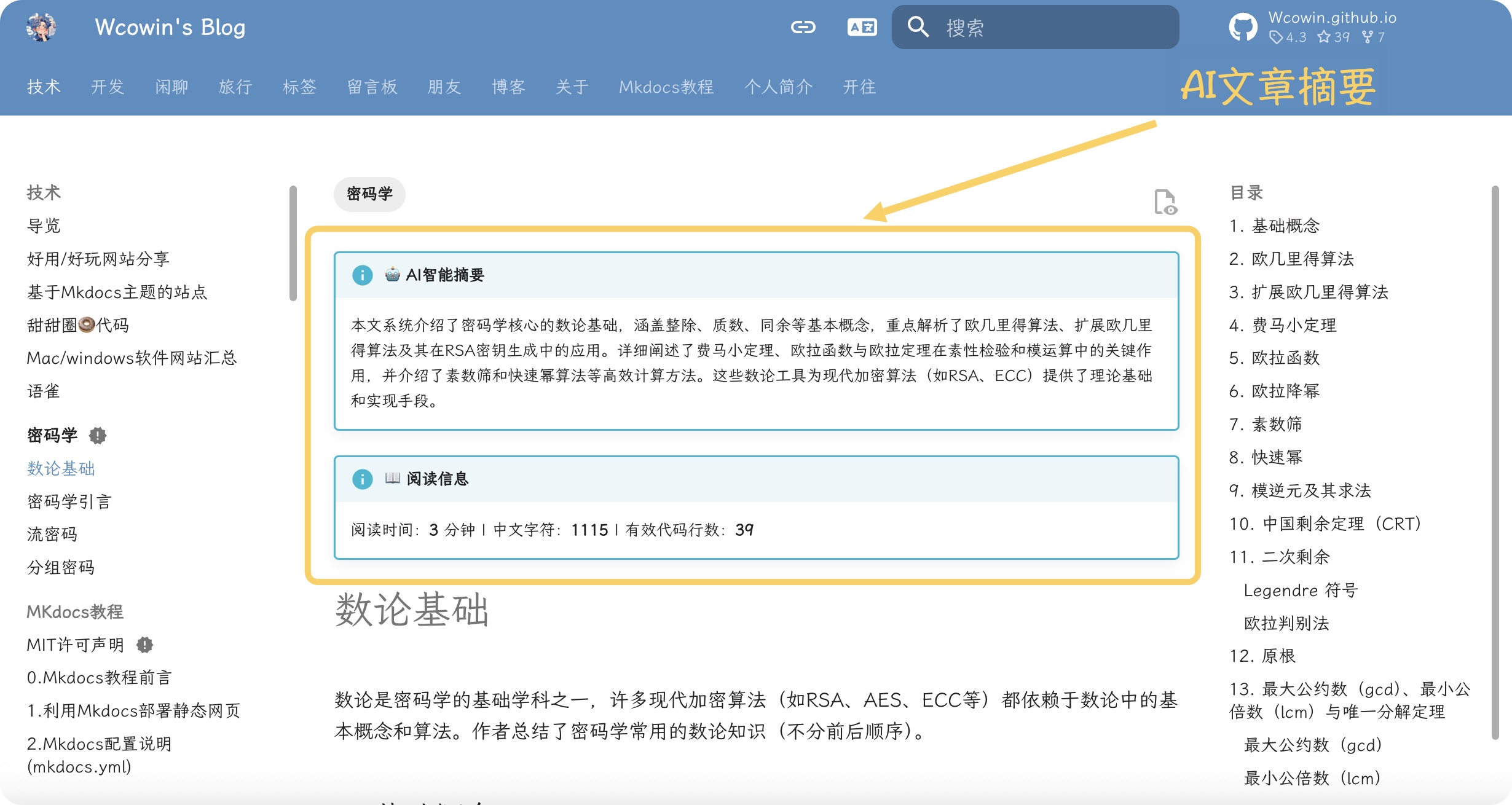
+## 🎨 显示效果
+
+### AI摘要显示
+```markdown
+!!! info "🤖 AI智能摘要"
+ 本文详细介绍了MkDocs hooks的开发和使用方法,涵盖AI摘要生成、阅读时间统计等功能实现。通过DeepSeek API集成和智能缓存机制,为技术文档提供自动化的内容增强服务。
+
+# 您的文章标题
+文章内容...
+```
+
+### 阅读信息显示
+```markdown
+!!! info "📖 阅读信息"
+ 阅读时间:**3** 分钟 | 中文字符:**1247** | 有效代码行数:**45**
+
+# 您的文章标题
+文章内容...
+```
+
+**实际效果:**
+
+
+### API花费
+一次大约0.03-0.05元(中大型文档)
+可以说相当经济实惠了!
+
+#### 免费openai额度获取
+
+推荐使用:[chatanywhere](https://github.com/chatanywhere/GPT_API_free?tab=readme-ov-file#%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8 )
+
+申请好后得到sk-开头的密钥,在ai_summary.py的多AI服务配置部分替换为以下内容:
+
+```python
+'openai': {
+ 'url': 'https://api.chatanywhere.tech/v1/chat/completions',
+ 'model': 'gpt-3.5-turbo', # 或 'gpt-4', 'gpt-4-turbo'
+ 'api_key': os.getenv('OPENAI_API_KEY', 'your_openai_api_key'),
+ 'max_tokens': 150,
+ 'temperature': 0.3
+},
+```
+
+```python
+# 默认使用的AI服务
+self.default_service = 'openai'
+```
+
+
+但是我这里也推荐使用[DeepSeek](https://platform.deepseek.com/usage) API,额度充足且性能优秀。
+
+## ⚙️ 高级配置
+
+### 自定义API服务
+```python
+# 支持其他AI服务
+self.api_config = {
+ 'url': 'https://your-api-endpoint.com/v1/chat/completions',
+ 'model': 'your-model',
+ 'headers': {
+ 'Content-Type': 'application/json',
+ 'Authorization': 'Bearer YOUR_API_KEY'
+ }
+}
+```
+
+### 自定义提示词
+```python
+# 修改AI摘要的提示词
+def generate_ai_summary(self, content, page_title=""):
+ prompt = f"""您的自定义提示词...
+
+ 文章标题:{page_title}
+ 文章内容:{content[:2500]}
+ """
+```
+
+### 缓存配置
+```python
+# 修改缓存过期时间(天数)
+cache_time = datetime.fromisoformat(cache_data.get('timestamp', '1970-01-01'))
+if (datetime.now() - cache_time).days < 30: # 改为30天
+ return cache_data
+```
+注意注意注意!!!
+切换api服务后,要删除site/.ai_cache这个缓存文件,才可以重新生成摘要!!!**(这个问题已经解决了,切换api服务后,会自动删除缓存文件,无需手动删除)**
+
+
+
+### 自定义摘要格式
+```python
+def format_summary(self, summary, ai_service):
+ """自定义摘要显示格式"""
+ return f'''!!! note "✨ 自定义摘要"
+ {summary}
+
+ *由 {ai_service} 生成*
+'''
+```
+
+## 🌍 多语言支持
+
+### 英文内容优化(Todo)
+```python
+# 阅读时间计算(英文:200词/分钟)
+def calculate_english_reading_time(word_count):
+ return max(1, round(word_count / 200))
+```
+
+### 其他语言扩展(Todo)
+```python
+# 支持日文、韩文等
+JAPANESE_CHARS_PATTERN = re.compile(r'[\u3040-\u309F\u30A0-\u30FF]')
+KOREAN_CHARS_PATTERN = re.compile(r'[\uAC00-\uD7AF]')
+```
+
+## 📊 性能优化
+
+- **LRU缓存**:函数级别缓存提升性能
+- **正则预编译**:提高文本处理速度
+- **智能过滤**:减少不必要的API调用
+- **异步支持**:可扩展为异步处理(TODO)
+
+## 🤝 贡献指南
+
+我们欢迎各种形式的贡献!
+
+1. **Fork** 这个仓库
+2. 创建您的特性分支
+3. 提交您的更改
+4. 推送到分支
+5. 打开一个 **Pull Request**
+
+### 开发环境设置
+```bash
+# 克隆仓库
+git clone https://github.com/Wcowin/mkdocs-ai-hooks.git
+cd mkdocs-ai-hooks
+
+# 安装依赖
+pip install -r requirements.txt
+
+```
+
+## 📝 更新日志
+
+### v1.0.0 (2025-06-03)
+- ✨ 初始发布
+- 🤖 AI智能摘要功能
+- 📖 阅读时间统计功能
+- 💾 智能缓存系统
+- 🎯 灵活配置选项
+
+### 计划功能
+- [x] 多AI服务支持(OpenAI、Claude等)
+- [x] 自动选择最佳API
+- [ ] API密钥安全处理(重要)
+- [ ] 批量处理模式
+- [ ] 统计数据导出
+- [ ] Web界面配置
+
+## 🐛 问题反馈
+
+如果您遇到任何问题,请在 [Issues](https://github.com/Wcowin/mkdocs-ai-hooks/issues) 中提交。
+
+提交问题时请包含:
+- MkDocs版本
+- Python版本
+- 错误信息
+- 复现步骤
+
+## 📄 许可证
+
+本项目采用 [MIT License](LICENSE) 开源协议。
+
+## 🙏 致谢
+
+- [MkDocs](https://www.mkdocs.org/) - 静态站点生成器
+- [Material for MkDocs](https://squidfunk.github.io/mkdocs-material/) - 优秀的主题
+- [DeepSeek](https://deepseek.com/) - AI API服务
+- 所有贡献者和使用者
+
+# Connect with me
+
+
+
+**Telegram**
+
+
+
+  +
+
+
+
+
+
+**Wechat**
+
+
+ +
+
+
+
+
+
+## Star History
+
+[](https://www.star-history.com/#Wcowin/mkdocs-ai-hooks&Date)
+
+
+## 请作者喝杯咖啡
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+ 如果这个项目对您有帮助,请给它一个 ⭐ Star!
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+
+📝 本项目致力于让MkDocs文档更加智能化和用户友好。如有建议或想法,欢迎交流!
\ No newline at end of file
diff --git a/docs/overrides/hooks/__pycache__/ai_summary.cpython-311.pyc b/docs/overrides/hooks/__pycache__/ai_summary.cpython-311.pyc
index 18abe37f9d71c4c6a6522854739f867f904485c1..fcbce627799349b98490f7f1c9c32dddfcaac8b4 100644
GIT binary patch
delta 11470
zcmbt)32+4d?@JUZiuWm5w?awONQ!NVA_byB5)ud?-GB}(IIwGc
zz+P=kxowM?$P+rzILu~jF{8xA*m5FgQX5ycwhE2uDRO&Di85>I*vwAoiL;YZ?bPmj
z-2iyV&ZK6Vjo1Ib|K7jOOLBZ%+9PkK&jWrSDzHe|k=K@lf)l$KIIN1oJEn&*g<28ujJ
z)af2#`QbWJPz<@llknA0?yxuPoAN?h>!%~59=B)G>&aGg<>!X{DCDjZUg9K45hrC7
z3DwCd+m(MP{ZbyKg%-3_9;Jh?j?zPso-&B-T
z8)pyd(PyZ{dgAHax~9#KHEr0y@;FECAK7%yzcMa)^v7EUodLxV;tG}`~nW!
z295y&ro^1>S4Ad85R(Lz_bqY*G16Kx6cm9=d9y(Fr{qY~acVfy>TPar9FBC2kB<*W
zwzrCzR%&egbX0rh%$cqA0{|bX&zu@LbGqToqnwe(#zsH_9A@etse4b2^q+3%kLH#Q
zp91vo>EYT_BXy@6hU*@&U&+gl_jf?U0wItdfuseQhY@5GK|yvFzM)HkjF}W&tL}>
z;UIEdasyQQ;S63Blv9_maV6t%``z%l;2RGMDi1U1rbB}2TrlkS1q9WUJM4Fl398Vg
zaC{OPQvr`J>=o2g!N5e28WS{A?sML8pWiF!sG#SZmzL7lKgL7*LSaD{3Nqmd+Ka70
z`hu5cCcS=4(?RHT*ym*gUHDSSE78|kX*tfbRum1Rl#hn4o`Vm2L*5@3WHdDH2~LHu
z$vn@bFW_aoqaNrrGa7P-!(JLXx%B%(OSh?V2^qOj5jRg!N?|P_tcaxFfr`i-sDG6&
zvB3Tgdjnwxb&E)*&~%f>*a6LUa^xnX`3b3}ZBRs0Y`3n-egK>qs*%MDCqYRXMt8U@`2AH<`I5=bwjf-jCw?D{W^{p9$~5|dx4
zrBMRXAg9=`*{&;T6mIO^ym}>_i>Vj$wkm0qs_c*QJUi(lkODyv8KeIMQ`$o(29F;Y
zJaBjq9Lg}9pgOrUzi`s%b5!s`fc60$gNH^y~DZHj(Uei4e-zj0P4jwjQ4qG9njry+DQxhGv{mMm)PObvOJtx`ZWaD
zL;6(&FR-tc*5*79$vUmrE855YthCpb01Sib5qcy&u;g~v4)W_apK?8|YMDW1m=A*f
zj|jes;6EXF1whmeqI-LDbIWjKe7t!Z!foU1o$7b;vGqEcAluq3kj&a9nX5TUK4kx?
zW+!Zt*4h&!`5yanT`4U7f37=1{vY;H-L_(JB5+qd#D#x21mF?5^&u`O`;R?6b+;iw
ze+1w=a{4_?{{#WrGwF$ah8{-DPuUywyUBd^v-)j0SSL){4-x-9+tTn($!$zxE%eU;
zd>&^3yK~F70+CZee*i=g+%pf}{n7mo-=%M{FK?OuBPuCkUu)c^NjLu?``;S>yMAp+
zSoV8c3krS!wSqnf`T})^^uhp!{x18gt&C#krVYTWM&3gG#`>po
zVmWkMEN4!`{;Df)y8<|2f2~=?(?&`;Z3B!V*R3;Vs2
zELvcH({`;BPluppy!3gW$192efz;7g09$7j3Yf`Y#7~XF=fWuMbyKL)eSz_yU}pop
z_PAgN^T`uIlPX)xgxz6=egi6?@mSJl#Rew4fCd#aji?BM7Z9%y?IjIEd(h69q`!wH
z{{z8GSez?qrct+VG_8i{6ymKCKAvq9`$YdO6xCUz^Zz=MDMDbdfK>-(q;EpVeS8!}
z>G4f?16~>jvDT1a$cz^qHX&z&ttIG011gTT6eHw-br3Qe02518?xGfz
z=G7?LbTFHeMy186*I|>=>voCXWovQb2%xujEVUd?wH*HVBG>X1-|`fvX-XJorshuGEhtLl0D+fr(LuH4)k|fasj|*R2UoV2FWWm~T(&|F^KXjD&N;w42WIvym(|5*4&Jd9CW{U%9RL2)eA_-q!OPhW^0tFX@rC~66(x%X
z7Zta(eCI((!OPhW@wP)r+o5G=`I56eqcMn1mUasH>UvMNTzIU@kM;2Re
zb@4rilFlRWas@+t!BDbb2!@+ixMXWc*&5~tmn-U*D;k%pn^)C}p8Qn;z^8;F&;A(#
z$O14Dm9G@)fQUa;;<8
zYQNg`YS-*(&f36R8|KG3YwN;A&N`4Z4BW+SLZgQE+pm9^Z4q-Ys{!GQLKpicW5
z^aIFkvJ?Ol?PIsOtRPbANt*py?>5k)|F!o(<0Gs_6c+a}g}j2A_J;g!5LFza4k17@
zoE~I%_7zxAsMM(>5%6n7zs{cPD=ZdU&6=yA_p#^`0MYt%!*+7)=Fj{3$YyaAaD1|l
z8d9hre`^3N=yY;g79&uoNe}9D7e&Too0I_(Wvlr^L|Ntghls$OSl^uNbDI+l03`cE
zHQ_9X4-#$typFFATfiVR8HPD6XrO#{SnW_u%fXl-d+h9cEta@FLjXEo9xhzV#pIMC
z3Rd?i)Y|KUsX|-WxBjymR&bU%h?r^##yopM3DG
z`*Y7ecvHH5kd|!qFJtOS1WzG2hTu4YA0Rji09-a-fO3N`
zZuSHt;QNX)T@vZ?DL2FjXh2h$?SvXd^gZZROnr*rHvsG#{2;`x0FX9T{0r3MpP`Wc
zXCM=WG@KswvL&Cl)Gb*WQ1C)A*VtOGC=iF#p7YnzMBBmd-T3a>-Jg
zveeF7=AYy&ZM>x|jjvd;)TAsm^UC=A1Te?)?%>W5~yfXOa+Hhm*F^1&?-1T+9+7|)AGwd0V7k7hGJa3
ziB}iX(Rk7_l)sGOiPJ{Vnvg8S4d)A2CaN8Qh+*yUh59;L4LuPLT~voizzqimqG|w;
ztMou=_CZ-?%>(e;ZU9$_39y+@7fh2eQu2oSZKn1c`7!c}>~i6;w3;AASNl6MNn0qy
zLx^2Kvj#r&B7kTI%If&$v%0kxB3y1i(+>#=g?Y<9(gbQ@MA3@RoxoX~tOfwj5O?#7`25DD{I*m+
zT5$OTeEvW}zg+A{Y6|Y=xmJlHEyT$HB=)Qn7GEov+p?hK3fuX@_Qb*E_8m$4{+Z~K
zy(VR^nI}1WJ#VjHvNxyf&78f3x3?tiEw{%K@%dsVk=c0|P
z?&quf0ma#l@U|m~J$DKnvnRe*bgd|H5XgatkmVH4?w?o0`PwIv4t$r*uDOGpd27-P
zMiW+QFJ8*8PvzIo_ky?2qr-pK1jZMc)3lEC_jgUDNloeF0u1-PD8NE6moJjI@hS3~
zU@n9qpLr6bW}KvC&uL;Z_HcDs85}|&QvjKKBN_~NPBalX$Lu{~E54w@GVm8hD5CIqa?
zb3VTxY77UlUXL58|eH;r^(6=oo;CvZko9X=f0o=fO*MMe*_?
z?Dd4butsWh__0`dKIntI!WTd$4BiGNV21npqOvmh^}??oe$~}cSu7TnH8ezJjg4_g
z0J5aeAw`}*3UB{mu+7ngw;yp!F
z(M$QxLxu^t15pj-W57kY)QuzX2kGvpe$4GThY~zMb#G8ra)SMro-O6KVRFUAqebr-
z53$SjZ&|9;V@oxdG!Cv?D$K5b*Hn+FVK;ORPxyBD{T2{Q?d*bQ2%5OJ)vuUA{EAQaTJCfx?i>*H%cz@vIR<37=?-@d(jjuQZ0@*8&{n^p8
z|J>8kbQ>xc7bW9ED)5@?-+P$uV83gi>g-`Um^2=oYfXe_E+pcR-1Lgwt5XT&e-Oy&
zM`Z0IvhERi>JfQbAp0JX-Fu;Pq9ZEW0Z*bKP^VmrK;s=8+@1s|2%4p(0VCwEzaLw}
z(?!@dv`SrPKzU1o!V0)(`R56W50JVX!0*wAP&wi1Dg%<5BDh{NnAXdLB!ohY`#Ix&
z9-w|duiuXWo&xadXTZr2KZ?pgBX{zU(qnN>eM2FuTtd3bOM$e*|0)@QMgP9Q8AeMi{j9kd=s+Flm=A0*u@RLx@@D#PifDI
zji(1gfC~ctdwe62c;x^W4$}~lrgZBWC_QL@gXob<+F#Q9EAPMd;KpCxoBh%K>+ehP
znhwN7+WeHlC0$n34$15*9Dm83|(@p}gn4{@{lC^cUP{CQB4r
zjM<)((wf%hRxt(tAOIKeqI=Vi>nx})_$V+f1U1;-81sezdC2SWK|Nbw3q5QBn&WT<
z_&M<@8YFJ|%Fv7{(KWz;K<379&#xgvzm5Q-Qc?u#|3OO7Vzhb`dm@mdVvu3;og&iz
zPXN&dln4+mQ^y~RY5zU6%KQ@$iJ=99`Eu7QeJ}SV3%AUBIejayZ^a{1xNI$$X+!(E
z;I%H^TD4?tOj#S}DRA4ZoxHU(p;=Wa93T@i0PO!&15r?mAw)5bSd!Rx$CP_HesNYk
zSHPL-c~d=9oKv!Fcg#d)BCB#puWBHo`PzZ2hh9B2S3O_O*&2CUV?w*Ewh$_GFJL%mPNQF#p@X0B{uya=i4S6xZb7>BHF)Q)@WQH95o=Sz@W8~L~H#KmMaw8ZeyEk`h<<=`J
zm*3cVfc?9Hu{bD?yMU&DiQpFqFdJ123=FvF9k7s~v&-pzNC>2h9zX;LX;2O>P~s6F
z&FC7uNuYlRKrp8762K|MOAq=V04XUIWRsN2L%>BVp%2$px%S6ySX5vWFbnL%9f5tM
zId@hyd*PZ1me!mrg8BA^>c8q=%P;P|-G1xvT7Fq+fVEE(16rF4vKMYdI
zRH9)+&;|(H!1PcM&jF~2$pI?gRDenx0w
zze{oYqd)-OxIRx(pQ|#`Hcc+)m&4RT0;UzSI}dNj`p>V=N;Cj-fL=w~PGs0mi0qIB
z_8zD%lSc+IopXYG{21YqiN|OwB(fLVaZr()Bhj#0q^LAL`SF|gE|U}!
zI|^HCal#6K4kpZGT{2arOjUCe^HI*!&6~QDnr?A4-;p0ajHa&zo3pXs-&qwujZKar
zKzl&CnZ#R1>F)A-m=bRye~+n85TG2VF_J=~T_%cRvHvtKD7_bPA7Kjb5Tv7qmj^Tg
zE&P~Xpm-+pXCYQ)9ZLNwkp(n6_{59xoutySO00u>Wu?lzRU!+XAg#)dRU!-O%ajnA
z$%4IP6_RJcVX|ClTP3n!KWSIOS^yMq%It%;pWSqIT_>Xlac*%T;NPuYhYu}kQ50?hgbMIq02NXvBoQZ=g8{fu26dYK
zuc0BR;R)O-ML_rrv7#?s(zCzVYjcQ;wGT?+`at}@k|wO*i{LL=v~ogF!z-
zqj@f_r_>`H7L7G;TK7kqUI=SM{N8^07?i?GFiY(4zM(zKL}_y4yQ*+&NSN-=ho6f0
S&(@dj&t-qPZ?6LT{r>?_JC6SV
delta 3792
zcma)9YfxLq6}~H7y(J`rkdOcy@kkJF3^7S$W57I&gCDU;(qJ%_xz|PnBxSF#4HW@r
zoK!#3)XrvVw;_czu8r#?Ln=45TjI27J4rL0j6^j>zSB&dNlEPKbfQe0AAS7j*?V~e
zJDus(>bqypp4~lr_Ut)(f15xTPocC6CX=3l=a28z_y5^*IxP#0p1ya>xPob8IQAsN
zsm?1H<`Vqnr%R(?c+GjJTv}!^U0P1dsZXLV9j7_Tbm=*?k8$g6(e_<#B(i(Fp?-L4
zId6y$`G)wum7YK>kNoAMP&vc!Oc&yquG9a~qBNpH8+2w)Cyi_-<;bB@z{nO7KqZQ|
z81fRjtmYWtq(u$vQ%K>~kUq^L1Z$6LbTF9k0z1^9R!g>(Qn
zi!cRn7Gxuh#*b}sm%e~M#QQ@6)n5|3-}E5b
zLIhI{vPCbL-bE@AVVpyP=E^J+okYza_X#0EWCKCoFR}wdz)#*Xm!k~wH*+(x61Sxu
zHAed_i;9dwkjKTe6FP=-XyqPqFr#^#j)SRYxQaIFd_v%G01tUXxRf%>D3j%ehk~N6
z<#-<-4EX|nQ5D2Kf5@$tmWnr08KW>fG~~r2y|5!*TtoZTQa<7ZHN5G%>5?cbUGN^|
zdu4f2V69N^0j`iwhAhtLlh&Oo%c$u5wj7X~O5-weroatyzbUYz7IMAdMPw%a
zLRTg=E`FH8P71pyG>~(J#ip%5x^=R7UF3S&EDlr`zk5lLeSRIjaP7rf-Gh&FQs@g<{1zR4a{9~l0>h;`}
zQSh_>qo;y&R##_9Jz0Dlgoddb-hAWQXK%lON65?7GylgREV;0;TDvs;D7mrmx@UE#
z=<2|Mf`h)0sPy_rM71{v$B@IAHn0N$pWkg<+Ct#qesa4;a1Bv%0zjayk(YOHc|RNE
z!{H!*DRYolYAetOBv$(^UB#?EZuKOro@n)bJj%#EGw{Md%vBS&)h2AUv%_)QW^!>;
z4qFs=){#GKIs@^okHQ46!pzPPf`g)%FbX*F8B!=n0q`^jII#
zNQ4BOBCHsokwAI|R7C$^j#lc+OsmP8J2J`N_m~UER3Y=S48w#KoRVYD!yaFv`z$?U
zYBJU3aH!5B;KF~2s|joHePPYCjx=^<)~KKtILc}g7=v&>rdy+r<}Q75b6;5_p}k8Y
zhYd5+da7+U8&=;rMOZ7`2ki#hUh@s@obC=4^mk3LVT0ig8RK0tIpp~V9NDU{HmnP)
zIn$(atsdaj*B)@(3$1JUWBRb3OB)4yg%L%_LgwLI@|-8H0rx_En1=7v6gio<`0O)_
zZ(LnG_tVd&UjKaVxtqU;-hAgfpPoK@^Zbd=UYz7
zqDJ8HQC}Y~9XZ?qEO#22-s~91`+$~w7dKEr_ONe|hx3m6dV`Q`aXw{gj_@IGD1>nx
z6|SV%q^FV62pp1+
zw^*wrP4!-1?~<~s*`+@;G$z-o
zH+vFhPl`dhoMc9JWcQ7%oQ16F`K)Sa%JL+#JQ34ZYQ|`ejKvMP2}AC*a^6r7GZcJe
zTo+4!_)6#8m
z6ZWkUW73>`_Hf)>IDI^Bu8e6bu`T+KhBJ!tm8cKNKu$~GnIRtg@ichEo%!R6VG4Y<}_VP<0BfIPrrDzvXgZbc~7f!=>DQo2thb?5XIjgk+n9G-(SE+#H#cKIx
zCmQ5;uirbw%L=SqbmUl$e*}F-OUUW$4Dx)phQzj6(57fn%NCSPQ%c`T#DogX?6m&n
zGV<1y=Sd*(OB8-c
zfmTOZm&=uhe?>_}UOv7GgoyI+FDXNvuct>-jx0#Bw_7F004eodAg*4k^Bjl@DgY`A
z2N)>)W7^$Ctz}&sLms0C`{!h&*WaVGuxHh0k4=L604c%DrrCR5t6!~OY5n!4xm~OE
zq{^65E(a%dU`cQ3
zMk5U=uZ4O7rl5tta2;S`<(E?AtMn;m1-7F!Rb`5ifxOrE?fOzxRf<`GF0?_FnPOI;
z3BFli>34%XzdHH}_o^aGT0$0`ox0Vskwq(+J#5wB-vjR`B3F-;!r@pv(goiN4gL0q
z+zR|VXu))G@F7Fp9luI}?w6>d8A15kXAEUp0)EI3NBG{AyYu_Njv(@WfBrbNF@6UC
z(!fqiOE=zJN*w|aH8isf`VL{Lqx=;jSx!=d>WJxJcNq6y+RZ}&Zg`Nd#~(l|y^h+{^2{PjI)TG#c6#{#GGkziQZ-2e@Q3Ls>ua%{`{}+Y9z|Q~x
diff --git a/docs/overrides/hooks/ai_summary.py b/docs/overrides/hooks/ai_summary.py
index ee522b7..7d62e57 100644
--- a/docs/overrides/hooks/ai_summary.py
+++ b/docs/overrides/hooks/ai_summary.py
@@ -4,6 +4,7 @@ import hashlib
import requests
from pathlib import Path
from datetime import datetime
+from functools import lru_cache
class AISummaryGenerator:
def __init__(self):
@@ -41,6 +42,27 @@ class AISummaryGenerator:
'docs/index.md',
'develop/index.md',
]
+
+ # 初始化阅读统计相关的正则表达式
+ self.chinese_chars_pattern = re.compile(r'[\u4e00-\u9fff\u3400-\u4dbf]')
+ self.code_block_pattern = re.compile(r'```.*?```', re.DOTALL)
+ self.inline_code_pattern = re.compile(r'`[^`]+`')
+ self.yaml_front_pattern = re.compile(r'^---.*?---\s*', re.DOTALL)
+ self.html_tag_pattern = re.compile(r'<[^>]+>')
+ self.image_pattern = re.compile(r'!\[.*?\]\([^)]+\)')
+ self.link_pattern = re.compile(r'\[([^\]]+)\]\([^)]+\)')
+
+ # 支持的编程语言
+ self.programming_languages = frozenset({
+ 'python', 'py', 'javascript', 'js', 'typescript', 'ts', 'java', 'cpp', 'c',
+ 'go', 'rust', 'php', 'ruby', 'swift', 'kotlin', 'csharp', 'cs',
+ 'bash', 'sh', 'powershell', 'ps1', 'zsh', 'fish', 'bat', 'cmd',
+ 'html', 'css', 'scss', 'sass', 'less', 'yaml', 'yml', 'json', 'xml',
+ 'toml', 'ini', 'conf', 'dockerfile', 'makefile',
+ 'sql', 'mysql', 'postgresql', 'sqlite', 'mongodb',
+ 'r', 'matlab', 'scala', 'perl', 'lua', 'dart', 'tex', 'latex',
+ 'csv', 'properties', ''
+ })
def configure_folders(self, folders=None, exclude_patterns=None, exclude_files=None):
"""
@@ -207,7 +229,7 @@ class AISummaryGenerator:
clean_text = re.sub(r'\*([^*]+)\*', r'\1', clean_text)
# 分割成句子
- sentences = re.split(r'[。!?.!?]', clean_text)
+ sentences = re.split(r'[\u3002\uff01\uff1f.!?]', clean_text)
sentences = [s.strip() for s in sentences if len(s.strip()) > 15]
# 优先选择包含关键词的句子
@@ -246,10 +268,10 @@ class AISummaryGenerator:
total_length += len(sentence)
if selected_sentences:
- summary = '。'.join(selected_sentences) + '。'
+ summary = '.'.join(selected_sentences) + '.'
# 简化冗长的摘要
if len(summary) > 120:
- summary = selected_sentences[0] + '。'
+ summary = selected_sentences[0] + '.'
return summary
else:
# 根据标题生成通用摘要
@@ -263,49 +285,71 @@ class AISummaryGenerator:
return '本文深入探讨了相关技术内容,提供了实用的方法和解决方案。'
def process_page(self, markdown, page, config):
- """处理页面,生成AI摘要"""
- if not self.should_generate_summary(page, markdown):
+ """处理页面,生成AI摘要和阅读统计"""
+ # 检查是否需要显示阅读信息
+ show_reading_info = self.should_show_reading_info(page, markdown)
+
+ # 检查是否需要生成AI摘要
+ should_generate_ai_summary = self.should_generate_summary(page, markdown)
+
+ # 如果两者都不需要,直接返回原内容
+ if not show_reading_info and not should_generate_ai_summary:
return markdown
- clean_content = self.clean_content_for_ai(markdown)
+ # 计算阅读统计
+ reading_time, chinese_chars, code_lines = self.calculate_reading_stats(markdown)
- # 内容长度检查
- if len(clean_content) < 200:
- print(f"📄 内容太短,跳过摘要生成: {page.file.src_path}")
- return markdown
+ result_blocks = []
- content_hash = self.get_content_hash(clean_content)
- page_title = getattr(page, 'title', '')
+ # 处理AI摘要
+ if should_generate_ai_summary:
+ clean_content = self.clean_content_for_ai(markdown)
+
+ # 内容长度检查
+ if len(clean_content) >= 200:
+ content_hash = self.get_content_hash(clean_content)
+ page_title = getattr(page, 'title', '')
+
+ # 检查缓存
+ cached_summary = self.get_cached_summary(content_hash)
+ if cached_summary:
+ summary = cached_summary.get('summary', '')
+ ai_service = 'cached'
+ print(f"✅ 使用缓存摘要: {page.file.src_path}")
+ else:
+ # 生成新摘要
+ print(f"🤖 正在生成AI摘要: {page.file.src_path}")
+ summary = self.generate_ai_summary(clean_content, page_title)
+
+ if not summary:
+ summary = self.generate_fallback_summary(clean_content, page_title)
+ ai_service = 'fallback'
+ print(f"📝 使用备用摘要: {page.file.src_path}")
+ else:
+ ai_service = 'deepseek'
+ print(f"✅ AI摘要生成成功: {page.file.src_path}")
+
+ # 保存到缓存
+ self.save_summary_cache(content_hash, {
+ 'summary': summary,
+ 'service': ai_service,
+ 'page_title': page_title
+ })
+
+ # 添加AI摘要块
+ ai_summary_block = self.format_ai_summary(summary, ai_service)
+ result_blocks.append(ai_summary_block)
- # 检查缓存
- cached_summary = self.get_cached_summary(content_hash)
- if cached_summary:
- summary = cached_summary.get('summary', '')
- ai_service = 'cached'
- print(f"✅ 使用缓存摘要: {page.file.src_path}")
+ # 添加阅读信息块
+ if show_reading_info:
+ reading_info_block = self.format_reading_info(reading_time, chinese_chars, code_lines)
+ result_blocks.append(reading_info_block)
+
+ # 合并所有块并返回
+ if result_blocks:
+ return '\n'.join(result_blocks) + '\n\n' + markdown
else:
- # 生成新摘要
- print(f"🤖 正在生成AI摘要: {page.file.src_path}")
- summary = self.generate_ai_summary(clean_content, page_title)
-
- if not summary:
- summary = self.generate_fallback_summary(clean_content, page_title)
- ai_service = 'fallback'
- print(f"📝 使用备用摘要: {page.file.src_path}")
- else:
- ai_service = 'deepseek'
- print(f"✅ AI摘要生成成功: {page.file.src_path}")
-
- # 保存到缓存
- self.save_summary_cache(content_hash, {
- 'summary': summary,
- 'service': ai_service,
- 'page_title': page_title
- })
-
- # 添加摘要到页面最上面
- summary_html = self.format_summary(summary, ai_service)
- return summary_html + '\n\n' + markdown
+ return markdown
def should_generate_summary(self, page, markdown):
"""判断是否应该生成摘要 - 可自定义文件夹"""
@@ -340,8 +384,139 @@ class AISummaryGenerator:
# 默认不生成摘要
return False
- def format_summary(self, summary, ai_service):
- """格式化摘要显示"""
+ def calculate_reading_stats(self, markdown):
+ """计算中文字符数和代码行数"""
+ # 清理内容用于中文字符统计
+ content = markdown
+ content = self.yaml_front_pattern.sub('', content)
+ content = self.html_tag_pattern.sub('', content)
+ content = self.image_pattern.sub('', content)
+ content = self.link_pattern.sub(r'\1', content)
+ content = self.code_block_pattern.sub('', content)
+ content = self.inline_code_pattern.sub('', content)
+
+ chinese_chars = len(self.chinese_chars_pattern.findall(content))
+
+ # 统计代码行数
+ code_lines = self.count_code_lines(markdown)
+
+ # 计算阅读时间(中文:400字/分钟)
+ reading_time = max(1, round(chinese_chars / 400))
+
+ return reading_time, chinese_chars, code_lines
+
+ def count_code_lines(self, markdown):
+ """统计代码行数"""
+ code_blocks = self.code_block_pattern.findall(markdown)
+ total_code_lines = 0
+
+ for block in code_blocks:
+ # 提取语言标识
+ lang_match = re.match(r'^```(\w*)', block)
+ language = lang_match.group(1).lower() if lang_match else ''
+
+ # 移除开头的语言标识和结尾的```
+ code_content = re.sub(r'^```\w*\n?', '', block)
+ code_content = re.sub(r'\n?```$', '', code_content)
+
+ # 过滤空代码块
+ if not code_content.strip():
+ continue
+
+ # 计算有效行数
+ lines = [line for line in code_content.split('\n') if line.strip()]
+ line_count = len(lines)
+
+ # 如果有明确的编程语言标识,直接统计
+ if language and language in self.programming_languages:
+ total_code_lines += line_count
+ continue
+
+ # 检测是否为代码内容
+ is_code = self.is_code_content(code_content)
+
+ if is_code:
+ total_code_lines += line_count
+
+ return total_code_lines
+
+ def is_code_content(self, content):
+ """判断内容是否为代码"""
+ # 命令行检测
+ command_indicators = [
+ 'sudo ', 'npm ', 'pip ', 'git ', 'cd ', 'ls ', 'mkdir ', 'rm ', 'cp ', 'mv ',
+ 'chmod ', 'chown ', 'grep ', 'find ', 'ps ', 'kill ', 'top ', 'cat ', 'echo ',
+ 'wget ', 'curl ', 'tar ', 'zip ', 'unzip ', 'ssh ', 'scp ', 'rsync ',
+ '$ ', '# ', '% ', '> ', 'C:\\>', 'PS>', '#!/',
+ '/Applications/', '/usr/', '/etc/', '/var/', '/home/', '~/',
+ ]
+
+ if any(indicator in content for indicator in command_indicators):
+ return True
+
+ # 编程语法检测
+ programming_indicators = [
+ 'def ', 'class ', 'import ', 'from ', 'return ', 'function', 'var ', 'let ', 'const ',
+ 'public ', 'private ', 'protected ', 'static ', 'void ', 'int ', 'string ',
+ '==', '!=', '<=', '>=', '&&', '||', '++', '--', '+=', '-=',
+ 'while ', 'for ', 'if ', 'else:', 'switch ', 'case ',
+ ' 1 and any(line.startswith(' ') or line.startswith('\t') for line in lines):
+ return True
+
+ if '<' in content and '>' in content:
+ return True
+
+ if any(char in content for char in ['{', '}', '(', ')', '[', ']']) and ('=' in content or ':' in content):
+ return True
+
+ return False
+
+ def should_show_reading_info(self, page, markdown):
+ """判断是否应该显示阅读信息"""
+ # 检查页面元数据
+ if page.meta.get('hide_reading_time', False):
+ return False
+
+ # 获取文件路径
+ src_path = page.file.src_path.replace('\\', '/')
+
+ # 使用现有的排除模式检查
+ exclude_patterns = [
+ r'^index\.md$', r'^about/', r'^trip/index\.md$', r'^relax/index\.md$',
+ r'^blog/indexblog\.md$', r'^blog/posts\.md$', r'^develop/index\.md$',
+ r'waline\.md$', r'link\.md$', r'404\.md$'
+ ]
+
+ for pattern in exclude_patterns:
+ if re.match(pattern, src_path):
+ return False
+
+ # 检查页面类型
+ page_type = page.meta.get('type', '')
+ if page_type in {'landing', 'special', 'widget'}:
+ return False
+
+ # 内容长度检查
+ if len(markdown) < 300:
+ return False
+
+ # 计算中文字符数
+ _, chinese_chars, _ = self.calculate_reading_stats(markdown)
+ if chinese_chars < 50:
+ return False
+
+ return True
+
+ def format_ai_summary(self, summary, ai_service):
+ """格式化AI摘要显示"""
service_config = {
'deepseek': {
'icon': '🤖',
@@ -354,7 +529,7 @@ class AISummaryGenerator:
'color': 'tip'
},
'cached': {
- 'icon': '💾',
+ 'icon': '🤖',
'name': 'AI智能摘要',
'color': 'info'
}
@@ -362,10 +537,21 @@ class AISummaryGenerator:
config = service_config.get(ai_service, service_config['deepseek'])
- return f'''!!! {config['color']} "{config['icon']} {config['name']}"
- {summary}
-
-'''
+ return f'''??? {config['color']} "{config['icon']} {config['name']}"
+ {summary}'''
+
+ def format_reading_info(self, reading_time, chinese_chars, code_lines):
+ """格式化阅读信息显示"""
+ if code_lines > 0:
+ return f'''!!! info "📖 阅读信息"
+ 阅读时间:**{reading_time}** 分钟 | 中文字符:**{chinese_chars}** | 有效代码行数:**{code_lines}**'''
+ else:
+ return f'''!!! info "📖 阅读信息"
+ 阅读时间:**{reading_time}** 分钟 | 中文字符:**{chinese_chars}**'''
+
+ def format_summary(self, summary, ai_service):
+ """保持向后兼容的格式化方法"""
+ return self.format_ai_summary(summary, ai_service)
# 创建全局实例
ai_summary_generator = AISummaryGenerator()
@@ -390,5 +576,5 @@ def configure_ai_summary(enabled_folders=None, exclude_patterns=None, exclude_fi
ai_summary_generator.configure_folders(enabled_folders, exclude_patterns, exclude_files)
def on_page_markdown(markdown, page, config, files):
- """MkDocs hook入口点"""
+ """MkDocs hook入口点 - 统一处理AI摘要和阅读统计"""
return ai_summary_generator.process_page(markdown, page, config)
\ No newline at end of file
diff --git a/docs/overrides/hooks/test.py b/docs/overrides/hooks/test.py
new file mode 100644
index 0000000..777e6cc
--- /dev/null
+++ b/docs/overrides/hooks/test.py
@@ -0,0 +1,397 @@
+# 备份智能摘要代码
+import re
+import json
+import hashlib
+import requests
+from pathlib import Path
+from datetime import datetime
+from functools import lru_cache
+
+class AISummaryGenerator:
+ def __init__(self):
+ self.cache_dir = Path("site/.ai_cache")
+ self.cache_dir.mkdir(exist_ok=True)
+
+ # DeepSeek API配置
+ self.api_config = {
+ 'url': 'https://api.deepseek.com/v1/chat/completions',
+ 'model': 'deepseek-chat',
+ 'headers': {
+ 'Content-Type': 'application/json',
+ 'Authorization': 'Bearer sk-7dbcd6e21fb3417299b50aecff76c7bf'
+ }
+ }
+
+ # 📂 可自定义的文件夹配置
+ self.enabled_folders = [
+ 'blog/', # blog文件夹
+ 'develop/', # develop文件夹
+ # 'about/', # about文件夹
+ # 在这里添加您想要启用AI摘要的文件夹
+ ]
+
+ # 📋 排除的文件和文件夹
+ self.exclude_patterns = [
+ 'liuyanban.md', 'link.md', '404.md', 'tag.md', 'tags.md',
+ '/about/', '/search/', '/sitemap', 'index.md', # 根目录index.md
+ ]
+
+ # 📋 排除的特定文件
+ self.exclude_files = [
+ 'blog/index.md',
+ 'blog/indexblog.md',
+ 'docs/index.md',
+ 'develop/index.md',
+ ]
+
+ def configure_folders(self, folders=None, exclude_patterns=None, exclude_files=None):
+ """
+ 配置启用AI摘要的文件夹
+
+ Args:
+ folders: 启用AI摘要的文件夹列表
+ exclude_patterns: 排除的模式列表
+ exclude_files: 排除的特定文件列表
+ """
+ if folders is not None:
+ self.enabled_folders = folders
+ if exclude_patterns is not None:
+ self.exclude_patterns = exclude_patterns
+ if exclude_files is not None:
+ self.exclude_files = exclude_files
+
+ def get_content_hash(self, content):
+ """生成内容hash用于缓存"""
+ return hashlib.md5(content.encode('utf-8')).hexdigest()
+
+ def get_cached_summary(self, content_hash):
+ """获取缓存的摘要"""
+ cache_file = self.cache_dir / f"{content_hash}.json"
+ if cache_file.exists():
+ try:
+ with open(cache_file, 'r', encoding='utf-8') as f:
+ cache_data = json.load(f)
+ # 检查缓存是否过期(7天)
+ cache_time = datetime.fromisoformat(cache_data.get('timestamp', '1970-01-01'))
+ if (datetime.now() - cache_time).days < 7:
+ return cache_data
+ except:
+ pass
+ return None
+
+ def save_summary_cache(self, content_hash, summary_data):
+ """保存摘要到缓存"""
+ cache_file = self.cache_dir / f"{content_hash}.json"
+ try:
+ summary_data['timestamp'] = datetime.now().isoformat()
+ with open(cache_file, 'w', encoding='utf-8') as f:
+ json.dump(summary_data, f, ensure_ascii=False, indent=2)
+ except Exception as e:
+ print(f"保存摘要缓存失败: {e}")
+
+ def clean_content_for_ai(self, markdown):
+ """清理内容,提取主要文本用于AI处理"""
+ content = markdown
+
+ # 移除YAML front matter
+ content = re.sub(r'^---.*?---\s*', '', content, flags=re.DOTALL)
+
+ # 移除已存在的阅读信息块和AI摘要块
+ content = re.sub(r'!!! info "📖 阅读信息".*?(?=\n\n|\n#|\Z)', '', content, flags=re.DOTALL)
+ content = re.sub(r'!!! info "🤖 AI智能摘要".*?(?=\n\n|\n#|\Z)', '', content, flags=re.DOTALL)
+ content = re.sub(r'!!! tip "📝 自动摘要".*?(?=\n\n|\n#|\Z)', '', content, flags=re.DOTALL)
+
+ # 移除HTML标签
+ content = re.sub(r'<[^>]+>', '', content)
+
+ # 移除图片,保留alt文本作为内容提示
+ content = re.sub(r'!\[([^\]]*)\]\([^)]+\)', r'[图片:\1]', content)
+
+ # 移除链接,保留文本
+ content = re.sub(r'\[([^\]]+)\]\([^)]+\)', r'\1', content)
+
+ # 移除代码块,但保留关键信息
+ content = re.sub(r'```(\w+)?\n(.*?)\n```', r'[代码示例]', content, flags=re.DOTALL)
+
+ # 移除行内代码
+ content = re.sub(r'`[^`]+`', '[代码]', content)
+
+ # 移除表格格式但保留内容
+ content = re.sub(r'\|[^\n]+\|', '', content)
+ content = re.sub(r'^[-|:\s]+$', '', content, flags=re.MULTILINE)
+
+ # 清理格式符号
+ content = re.sub(r'\*\*([^*]+)\*\*', r'\1', content) # 粗体
+ content = re.sub(r'\*([^*]+)\*', r'\1', content) # 斜体
+ content = re.sub(r'^#+\s*', '', content, flags=re.MULTILINE) # 标题符号
+
+ # 移除多余的空行和空格
+ content = re.sub(r'\n\s*\n', '\n\n', content)
+ content = re.sub(r'^[ \t]+', '', content, flags=re.MULTILINE)
+ content = content.strip()
+
+ return content
+
+ def generate_ai_summary(self, content, page_title=""):
+ """使用DeepSeek生成摘要"""
+ # 优化的提示词
+ prompt = f"""请为以下技术文章生成一个高质量的摘要,要求:
+
+1. **长度控制**:严格控制在80-120字以内
+2. **内容要求**:
+ - 准确概括文章的核心主题和关键要点
+ - 突出技术特点、应用场景或解决的问题
+ - 使用专业但易懂的语言
+ - 避免重复文章标题的内容
+3. **格式要求**:
+ - 直接返回摘要内容,无需任何前缀或后缀
+ - 使用简洁的陈述句
+ - 可以适当使用技术术语
+
+文章标题:{page_title}
+
+文章内容:
+{content[:2500]}
+
+请生成摘要:"""
+
+ try:
+ payload = {
+ "model": self.api_config['model'],
+ "messages": [
+ {
+ "role": "system",
+ "content": "你是一个专业的技术文档摘要专家,擅长提取文章核心要点并生成简洁准确的摘要。"
+ },
+ {
+ "role": "user",
+ "content": prompt
+ }
+ ],
+ "max_tokens": 150,
+ "temperature": 0.3, # 降低随机性,提高准确性
+ "top_p": 0.9
+ }
+
+ response = requests.post(
+ self.api_config['url'],
+ headers=self.api_config['headers'],
+ json=payload,
+ timeout=30
+ )
+
+ if response.status_code == 200:
+ result = response.json()
+ summary = result['choices'][0]['message']['content'].strip()
+
+ # 清理可能的格式问题
+ summary = re.sub(r'^["""''`]+|["""''`]+$', '', summary)
+ summary = re.sub(r'^\s*摘要[::]\s*', '', summary)
+ summary = re.sub(r'^\s*总结[::]\s*', '', summary)
+
+ return summary
+ else:
+ print(f"DeepSeek API请求失败: {response.status_code} - {response.text}")
+ return None
+
+ except requests.exceptions.RequestException as e:
+ print(f"DeepSeek API请求异常: {e}")
+ return None
+ except Exception as e:
+ print(f"AI摘要生成异常: {e}")
+ return None
+
+ def generate_fallback_summary(self, content, page_title=""):
+ """生成备用摘要(基于规则的智能摘要)"""
+ # 移除格式符号
+ clean_text = re.sub(r'^#+\s*', '', content, flags=re.MULTILINE)
+ clean_text = re.sub(r'\*\*([^*]+)\*\*', r'\1', clean_text)
+ clean_text = re.sub(r'\*([^*]+)\*', r'\1', clean_text)
+
+ # 分割成句子
+ sentences = re.split(r'[\u3002\uff01\uff1f.!?]', clean_text)
+ sentences = [s.strip() for s in sentences if len(s.strip()) > 15]
+
+ # 优先选择包含关键词的句子
+ key_indicators = [
+ '介绍', '讲解', '说明', '分析', '探讨', '研究', '实现', '应用',
+ '方法', '技术', '算法', '原理', '概念', '特点', '优势', '解决',
+ '教程', '指南', '配置', '安装', '部署', '开发', '设计', '构建'
+ ]
+
+ priority_sentences = []
+ normal_sentences = []
+
+ for sentence in sentences[:10]: # 处理前10句
+ if any(keyword in sentence for keyword in key_indicators):
+ priority_sentences.append(sentence)
+ else:
+ normal_sentences.append(sentence)
+
+ # 组合摘要
+ selected_sentences = []
+ total_length = 0
+
+ # 优先使用关键句子
+ for sentence in priority_sentences:
+ if total_length + len(sentence) > 100:
+ break
+ selected_sentences.append(sentence)
+ total_length += len(sentence)
+
+ # 如果还有空间,添加普通句子
+ if total_length < 80:
+ for sentence in normal_sentences:
+ if total_length + len(sentence) > 100:
+ break
+ selected_sentences.append(sentence)
+ total_length += len(sentence)
+
+ if selected_sentences:
+ summary = '.'.join(selected_sentences) + '.'
+ # 简化冗长的摘要
+ if len(summary) > 120:
+ summary = selected_sentences[0] + '.'
+ return summary
+ else:
+ # 根据标题生成通用摘要
+ if any(keyword in page_title for keyword in ['教程', '指南', 'Tutorial']):
+ return '本文提供了详细的教程指南,通过实例演示帮助读者掌握相关技术要点。'
+ elif any(keyword in page_title for keyword in ['配置', '设置', '安装', 'Config']):
+ return '本文介绍了系统配置的方法和步骤,提供实用的设置建议和最佳实践。'
+ elif any(keyword in page_title for keyword in ['开发', '编程', 'Development']):
+ return '本文分享了开发经验和技术实践,提供了实用的代码示例和解决方案。'
+ else:
+ return '本文深入探讨了相关技术内容,提供了实用的方法和解决方案。'
+
+ def process_page(self, markdown, page, config):
+ """处理页面,生成AI摘要"""
+ if not self.should_generate_summary(page, markdown):
+ return markdown
+
+ clean_content = self.clean_content_for_ai(markdown)
+
+ # 内容长度检查
+ if len(clean_content) < 200:
+ print(f"📄 内容太短,跳过摘要生成: {page.file.src_path}")
+ return markdown
+
+ content_hash = self.get_content_hash(clean_content)
+ page_title = getattr(page, 'title', '')
+
+ # 检查缓存
+ cached_summary = self.get_cached_summary(content_hash)
+ if cached_summary:
+ summary = cached_summary.get('summary', '')
+ ai_service = 'cached'
+ print(f"✅ 使用缓存摘要: {page.file.src_path}")
+ else:
+ # 生成新摘要
+ print(f"🤖 正在生成AI摘要: {page.file.src_path}")
+ summary = self.generate_ai_summary(clean_content, page_title)
+
+ if not summary:
+ summary = self.generate_fallback_summary(clean_content, page_title)
+ ai_service = 'fallback'
+ print(f"📝 使用备用摘要: {page.file.src_path}")
+ else:
+ ai_service = 'deepseek'
+ print(f"✅ AI摘要生成成功: {page.file.src_path}")
+
+ # 保存到缓存
+ self.save_summary_cache(content_hash, {
+ 'summary': summary,
+ 'service': ai_service,
+ 'page_title': page_title
+ })
+
+ # 添加摘要到页面最上面
+ summary_html = self.format_summary(summary, ai_service)
+ return summary_html + '\n\n' + markdown
+
+ def should_generate_summary(self, page, markdown):
+ """判断是否应该生成摘要 - 可自定义文件夹"""
+ # 检查页面元数据
+ if hasattr(page, 'meta'):
+ # 明确禁用
+ if page.meta.get('ai_summary') == False:
+ return False
+
+ # 强制启用
+ if page.meta.get('ai_summary') == True:
+ return True
+
+ # 获取文件路径
+ src_path = page.file.src_path.replace('\\', '/') # 统一路径分隔符
+
+ # 检查排除模式
+ if any(pattern in src_path for pattern in self.exclude_patterns):
+ return False
+
+ # 检查排除的特定文件
+ if src_path in self.exclude_files:
+ return False
+
+ # 检查是否在启用的文件夹中
+ for folder in self.enabled_folders:
+ if src_path.startswith(folder) or f'/{folder}' in src_path:
+ folder_name = folder.rstrip('/')
+ print(f"🎯 {folder_name}文件夹文章检测到,启用AI摘要: {src_path}")
+ return True
+
+ # 默认不生成摘要
+ return False
+
+ def format_summary(self, summary, ai_service):
+ """格式化摘要显示"""
+ service_config = {
+ 'deepseek': {
+ 'icon': '🤖',
+ 'name': 'AI智能摘要',
+ 'color': 'info'
+ },
+ 'fallback': {
+ 'icon': '📝',
+ 'name': '自动摘要',
+ 'color': 'tip'
+ },
+ 'cached': {
+ 'icon': '💾',
+ 'name': 'AI智能摘要',
+ 'color': 'info'
+ }
+ }
+
+ config = service_config.get(ai_service, service_config['deepseek'])
+
+ return f'''??? {config['color']} "{config['icon']} {config['name']}"
+ {summary}
+
+'''
+
+# 创建全局实例
+ai_summary_generator = AISummaryGenerator()
+
+# 🔧 自定义配置函数
+def configure_ai_summary(enabled_folders=None, exclude_patterns=None, exclude_files=None):
+ """
+ 配置AI摘要功能
+
+ Args:
+ enabled_folders: 启用AI摘要的文件夹列表,例如 ['blog/', 'docs/', 'posts/']
+ exclude_patterns: 排除的模式列表,例如 ['404.md', '/admin/']
+ exclude_files: 排除的特定文件列表,例如 ['blog/index.md']
+
+ Example:
+ # 只在blog和docs文件夹启用
+ configure_ai_summary(['blog/', 'docs/'])
+
+ # 在所有文件夹启用,但排除特定文件
+ configure_ai_summary([''], exclude_files=['index.md', 'about.md'])
+ """
+ ai_summary_generator.configure_folders(enabled_folders, exclude_patterns, exclude_files)
+
+def on_page_markdown(markdown, page, config, files):
+ """MkDocs hook入口点"""
+ return ai_summary_generator.process_page(markdown, page, config)
+
diff --git a/mkdocs.yml b/mkdocs.yml
index d1ead96..8b248e1 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -75,6 +75,7 @@ nav:
- 2.Mkdocs配置说明(mkdocs.yml): blog/Mkdocs/mkdocs2.md
- 3.解决Github Pages部署mkdocs自定义域名失效的问题: blog/Mkdocs/mkdocs3.md
- Mkdocs美化/补充:
+ - MkDocs文档AI摘要: blog/websitebeauty/MkDocs-AI-Hooks.md
- 添加Mkdocs博客: blog/Mkdocs/mkdocsblog.md
- 网页圆角化设计: blog/websitebeauty/yuanjiaohua.md
- 添加评论系统(giscus为例): blog/websitebeauty/mkcomments.md
@@ -312,5 +313,5 @@ extra_css:
hooks:
- docs/overrides/hooks/socialmedia.py
- - docs/overrides/hooks/reading_time.py
+ # - docs/overrides/hooks/reading_time.py
- docs/overrides/hooks/ai_summary.py
\ No newline at end of file
diff --git a/site/.ai_cache/608652015d8fccc03a9c1fb96962eb06.json b/site/.ai_cache/608652015d8fccc03a9c1fb96962eb06.json
new file mode 100644
index 0000000..d20a35b
--- /dev/null
+++ b/site/.ai_cache/608652015d8fccc03a9c1fb96962eb06.json
@@ -0,0 +1,6 @@
+{
+ "summary": "该项目为MkDocs文档系统提供AI驱动的智能摘要生成和阅读统计功能,支持多语言和多种AI服务API。核心特性包括自动生成80-120字高质量摘要、智能内容清理、高效缓存系统以及精准的阅读时间估算。通过灵活的配置选项,用户可实现文件夹或页面级别的控制,并自定义API服务和提示词。该方案具有经济高效、性能优化等特点,适用于技术文档和博客的自动化摘要需求。",
+ "service": "deepseek",
+ "page_title": "MkDocs文档AI摘要",
+ "timestamp": "2025-06-03T20:37:34.409741"
+}
\ No newline at end of file