mirror of
https://github.com/Wcowin/Mkdocs-Wcowin.git
synced 2025-07-20 17:06:34 +00:00
Compare commits
7 Commits
e2465b9581
...
f12ee99693
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f12ee99693 | ||
| a3efc6ccb7 | |||
| 9d455d6b81 | |||
|
|
367b8205d4 | ||
| 85a392130b | |||
| d7cd2e9703 | |||
| 739737bd32 |
@ -6,5 +6,5 @@
|
|||||||
"gemini"
|
"gemini"
|
||||||
],
|
],
|
||||||
"summary_language": "zh",
|
"summary_language": "zh",
|
||||||
"check_time": "2025-07-12T09:53:31.311564"
|
"check_time": "2025-07-15T15:54:02.605408"
|
||||||
}
|
}
|
||||||
@ -1 +1,9 @@
|
|||||||
|
<<<<<<< Updated upstream
|
||||||
|
<<<<<<< Updated upstream
|
||||||
|
{"cache_date": "2025-07-15", "page_authors": {}}
|
||||||
|
=======
|
||||||
{"cache_date": "2025-07-12", "page_authors": {}}
|
{"cache_date": "2025-07-12", "page_authors": {}}
|
||||||
|
>>>>>>> Stashed changes
|
||||||
|
=======
|
||||||
|
{"cache_date": "2025-07-12", "page_authors": {}}
|
||||||
|
>>>>>>> Stashed changes
|
||||||
|
|||||||
534
docs/blog/websitebeauty/recommend.md
Normal file
534
docs/blog/websitebeauty/recommend.md
Normal file
@ -0,0 +1,534 @@
|
|||||||
|
---
|
||||||
|
title: 为MKdocs页面添加相关文章推荐
|
||||||
|
tags:
|
||||||
|
- Mkdocs
|
||||||
|
status: new
|
||||||
|
---
|
||||||
|
|
||||||
|
# 为MKdocs页面添加相关文章推荐
|
||||||
|
|
||||||
|
## 步骤
|
||||||
|
|
||||||
|
`mkdocs.yml`中需要覆写文件夹overrides(没有的话新建一个)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
theme:
|
||||||
|
name: material
|
||||||
|
custom_dir: docs/overrides
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
在docs/overrides/hooks/下新建一个`related_posts.py`文件即可,内容如下:
|
||||||
|
|
||||||
|
具体配置根据自己仓库情况自行修改
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
from collections import Counter, defaultdict
|
||||||
|
from textwrap import dedent
|
||||||
|
import hashlib
|
||||||
|
import yaml
|
||||||
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
|
# 存储所有文章的信息和索引
|
||||||
|
article_index = {}
|
||||||
|
category_index = defaultdict(list)
|
||||||
|
keyword_index = defaultdict(set)
|
||||||
|
|
||||||
|
# 配置:需要索引的目录
|
||||||
|
INDEXED_DIRECTORIES = ['blog/', 'develop/']
|
||||||
|
|
||||||
|
# 配置:排除推荐的页面列表(支持精确匹配和模式匹配)
|
||||||
|
EXCLUDED_PAGES = {
|
||||||
|
# 精确路径匹配
|
||||||
|
'blog/index.md',
|
||||||
|
'develop/index.md',
|
||||||
|
# 可以添加更多排除的页面
|
||||||
|
# 'blog/special-page.md',
|
||||||
|
}
|
||||||
|
|
||||||
|
# 配置:排除推荐的页面模式(支持通配符)
|
||||||
|
EXCLUDED_PATTERNS = [
|
||||||
|
r'.*\/index\.md$', # 排除所有 index.md 文件
|
||||||
|
r'.*\/archive\.md$', # 排除所有 archive.md 文件
|
||||||
|
r'blog\/posts?\/.*', # 排除 blog/post/ 和 blog/posts/ 目录下的所有文章
|
||||||
|
# 可以添加更多模式
|
||||||
|
# r'blog\/draft\/.*', # 排除草稿目录
|
||||||
|
]
|
||||||
|
|
||||||
|
# 配置:相似度阈值和权重
|
||||||
|
SIMILARITY_CONFIG = {
|
||||||
|
'min_threshold': 0.15, # 提高最低相似度阈值
|
||||||
|
'weights': {
|
||||||
|
'keywords': 0.35, # 关键词权重
|
||||||
|
'tags': 0.30, # 标签权重
|
||||||
|
'categories': 0.20, # 分类权重
|
||||||
|
'path': 0.10, # 路径分类权重
|
||||||
|
'source_dir': 0.05 # 源目录权重
|
||||||
|
},
|
||||||
|
'title_similarity': 0.25 # 标题相似度权重
|
||||||
|
}
|
||||||
|
|
||||||
|
def is_page_excluded(file_path):
|
||||||
|
"""检查页面是否应该排除推荐"""
|
||||||
|
# 精确匹配检查
|
||||||
|
if file_path in EXCLUDED_PAGES:
|
||||||
|
return True
|
||||||
|
|
||||||
|
# 模式匹配检查
|
||||||
|
for pattern in EXCLUDED_PATTERNS:
|
||||||
|
if re.match(pattern, file_path):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def should_index_file(file_path):
|
||||||
|
"""检查文件是否应该被索引"""
|
||||||
|
if not file_path.endswith('.md'):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# 先检查是否被排除
|
||||||
|
if is_page_excluded(file_path):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# 检查是否在指定目录下
|
||||||
|
for directory in INDEXED_DIRECTORIES:
|
||||||
|
if file_path.startswith(directory):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def extract_keywords(content, title):
|
||||||
|
"""提取文章中的关键词,改进算法"""
|
||||||
|
# 移除YAML front matter
|
||||||
|
content = re.sub(r'^---\s*\n.*?\n---\s*\n', '', content, flags=re.DOTALL | re.MULTILINE)
|
||||||
|
|
||||||
|
# 移除代码块
|
||||||
|
content = re.sub(r'```.*?```', '', content, flags=re.DOTALL)
|
||||||
|
# 移除HTML标签
|
||||||
|
content = re.sub(r'<.*?>', '', content)
|
||||||
|
# 移除链接
|
||||||
|
content = re.sub(r'\[.*?\]\(.*?\)', '', content)
|
||||||
|
# 移除标题标记
|
||||||
|
content = re.sub(r'^#+\s+', '', content, flags=re.MULTILINE)
|
||||||
|
|
||||||
|
# 合并标题和内容,标题权重更高
|
||||||
|
title_words = re.findall(r'\b\w+\b', title.lower()) * 4 # 增加标题权重
|
||||||
|
content_words = re.findall(r'\b\w+\b', content.lower())
|
||||||
|
all_words = title_words + content_words
|
||||||
|
|
||||||
|
# 扩展停用词列表(包含中英文)
|
||||||
|
stopwords = {
|
||||||
|
# 英文停用词
|
||||||
|
'the', 'a', 'an', 'in', 'on', 'at', 'to', 'for', 'of', 'and', 'or', 'is', 'are', 'was', 'were',
|
||||||
|
'be', 'been', 'have', 'has', 'had', 'do', 'does', 'did', 'will', 'would', 'could', 'should',
|
||||||
|
'this', 'that', 'these', 'those', 'with', 'from', 'by', 'as', 'can', 'but', 'not', 'if', 'it',
|
||||||
|
'they', 'them', 'their', 'you', 'your', 'we', 'our', 'my', 'me', 'i', 'he', 'she', 'him', 'her',
|
||||||
|
# 常见无意义词
|
||||||
|
'about', 'above', 'after', 'again', 'all', 'also', 'any', 'because', 'before', 'between',
|
||||||
|
'both', 'each', 'few', 'first', 'get', 'how', 'into', 'just', 'last', 'made', 'make', 'may',
|
||||||
|
'most', 'new', 'now', 'old', 'only', 'other', 'over', 'said', 'same', 'see', 'some', 'such',
|
||||||
|
'take', 'than', 'then', 'time', 'two', 'use', 'very', 'way', 'well', 'where', 'when', 'which',
|
||||||
|
'while', 'who', 'why', 'work', 'world', 'year', 'years',
|
||||||
|
# 中文停用词
|
||||||
|
'的', '了', '和', '是', '就', '都', '而', '及', '与', '这', '那', '有', '在', '中', '为', '对', '等',
|
||||||
|
'能', '会', '可以', '没有', '什么', '一个', '自己', '这个', '那个', '这些', '那些', '如果', '因为', '所以'
|
||||||
|
}
|
||||||
|
|
||||||
|
# 过滤单词:长度>=2,不在停用词中,不是纯数字
|
||||||
|
words = [w for w in all_words
|
||||||
|
if len(w) >= 2 and w not in stopwords and not w.isdigit()]
|
||||||
|
|
||||||
|
# 返回词频最高的15个词
|
||||||
|
return Counter(words).most_common(15)
|
||||||
|
|
||||||
|
def extract_metadata(content):
|
||||||
|
"""提取文章元数据,支持YAML front matter"""
|
||||||
|
metadata = {
|
||||||
|
'title': "未命名",
|
||||||
|
'description': "",
|
||||||
|
'tags': [],
|
||||||
|
'categories': [],
|
||||||
|
'disable_related': False # 新增:是否禁用相关推荐
|
||||||
|
}
|
||||||
|
|
||||||
|
# 尝试解析YAML front matter
|
||||||
|
yaml_match = re.match(r'^---\s*\n(.*?)\n---\s*\n', content, re.DOTALL)
|
||||||
|
if yaml_match:
|
||||||
|
try:
|
||||||
|
yaml_content = yaml_match.group(1)
|
||||||
|
yaml_data = yaml.safe_load(yaml_content)
|
||||||
|
if yaml_data:
|
||||||
|
metadata['title'] = str(yaml_data.get('title', '未命名')).strip('"\'')
|
||||||
|
metadata['description'] = str(yaml_data.get('description', '')).strip('"\'')
|
||||||
|
metadata['disable_related'] = yaml_data.get('disable_related', False)
|
||||||
|
|
||||||
|
# 处理tags
|
||||||
|
tags = yaml_data.get('tags', [])
|
||||||
|
if isinstance(tags, list):
|
||||||
|
metadata['tags'] = [str(tag).strip() for tag in tags]
|
||||||
|
elif isinstance(tags, str):
|
||||||
|
metadata['tags'] = [tag.strip() for tag in tags.split(',') if tag.strip()]
|
||||||
|
|
||||||
|
# 处理categories
|
||||||
|
categories = yaml_data.get('categories', [])
|
||||||
|
if isinstance(categories, list):
|
||||||
|
metadata['categories'] = [str(cat).strip() for cat in categories]
|
||||||
|
elif isinstance(categories, str):
|
||||||
|
metadata['categories'] = [cat.strip() for cat in categories.split(',') if cat.strip()]
|
||||||
|
except yaml.YAMLError:
|
||||||
|
pass # 如果YAML解析失败,使用默认值
|
||||||
|
|
||||||
|
# 如果YAML解析失败,回退到正则表达式
|
||||||
|
if metadata['title'] == "未命名":
|
||||||
|
title_match = re.search(r'^title:\s*(.+)$', content, re.MULTILINE)
|
||||||
|
if title_match:
|
||||||
|
metadata['title'] = title_match.group(1).strip('"\'')
|
||||||
|
|
||||||
|
return metadata
|
||||||
|
|
||||||
|
def get_category_from_path(file_path):
|
||||||
|
"""从文件路径提取分类"""
|
||||||
|
parts = file_path.split('/')
|
||||||
|
if len(parts) > 2:
|
||||||
|
return parts[1] # blog/category/file.md 或 develop/category/file.md格式
|
||||||
|
elif len(parts) > 1:
|
||||||
|
return parts[0] # blog 或 develop
|
||||||
|
return "未分类"
|
||||||
|
|
||||||
|
def calculate_content_hash(content):
|
||||||
|
"""计算内容哈希,用于检测内容变化"""
|
||||||
|
return hashlib.md5(content.encode('utf-8')).hexdigest()
|
||||||
|
|
||||||
|
def on_files(files, config):
|
||||||
|
"""预处理所有文章,建立索引"""
|
||||||
|
global article_index, category_index, keyword_index
|
||||||
|
|
||||||
|
# 清空索引
|
||||||
|
article_index.clear()
|
||||||
|
category_index.clear()
|
||||||
|
keyword_index.clear()
|
||||||
|
|
||||||
|
processed_count = 0
|
||||||
|
excluded_count = 0
|
||||||
|
|
||||||
|
for file in files:
|
||||||
|
if should_index_file(file.src_path):
|
||||||
|
try:
|
||||||
|
with open(file.abs_src_path, 'r', encoding='utf-8') as f:
|
||||||
|
content = f.read()
|
||||||
|
|
||||||
|
# 提取元数据
|
||||||
|
metadata = extract_metadata(content)
|
||||||
|
|
||||||
|
# 检查是否禁用相关推荐
|
||||||
|
if metadata.get('disable_related', False):
|
||||||
|
excluded_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 再次检查是否在排除列表中(双重检查)
|
||||||
|
if is_page_excluded(file.src_path):
|
||||||
|
excluded_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 提取关键词
|
||||||
|
keywords = extract_keywords(content, metadata['title'])
|
||||||
|
|
||||||
|
# 获取分类
|
||||||
|
path_category = get_category_from_path(file.src_path)
|
||||||
|
|
||||||
|
# 构建文章信息
|
||||||
|
article_info = {
|
||||||
|
'title': metadata['title'],
|
||||||
|
'description': metadata['description'],
|
||||||
|
'tags': metadata['tags'],
|
||||||
|
'categories': metadata['categories'],
|
||||||
|
'path_category': path_category,
|
||||||
|
'keywords': keywords,
|
||||||
|
'url': file.url,
|
||||||
|
'path': file.src_path,
|
||||||
|
'content_hash': calculate_content_hash(content),
|
||||||
|
'source_dir': file.src_path.split('/')[0] # blog 或 develop
|
||||||
|
}
|
||||||
|
|
||||||
|
# 添加到主索引
|
||||||
|
article_index[file.src_path] = article_info
|
||||||
|
|
||||||
|
# 添加到分类索引
|
||||||
|
category_index[path_category].append(file.src_path)
|
||||||
|
for category in metadata['categories']:
|
||||||
|
if category: # 确保分类不为空
|
||||||
|
category_index[category].append(file.src_path)
|
||||||
|
|
||||||
|
# 添加到关键词索引
|
||||||
|
for keyword, _ in keywords:
|
||||||
|
keyword_index[keyword].add(file.src_path)
|
||||||
|
for tag in metadata['tags']:
|
||||||
|
if tag: # 确保标签不为空
|
||||||
|
keyword_index[tag.lower()].add(file.src_path)
|
||||||
|
|
||||||
|
processed_count += 1
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"❌ 处理文件 {file.src_path} 时出错: {e}")
|
||||||
|
|
||||||
|
print(f"✅ 已索引 {processed_count} 篇文章 (blog + develop)")
|
||||||
|
if excluded_count > 0:
|
||||||
|
print(f"📝 排除 {excluded_count} 篇禁用推荐或在排除列表中的文章")
|
||||||
|
print(f"📊 分类数量: {len(category_index)}")
|
||||||
|
print(f"🔤 关键词数量: {len(keyword_index)}")
|
||||||
|
return files
|
||||||
|
|
||||||
|
def on_page_markdown(markdown, **kwargs):
|
||||||
|
"""为每篇文章添加相关推荐"""
|
||||||
|
page = kwargs['page']
|
||||||
|
config = kwargs['config']
|
||||||
|
|
||||||
|
# 检查是否应该处理这个页面
|
||||||
|
if not should_index_file(page.file.src_path):
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 检查是否被排除
|
||||||
|
if is_page_excluded(page.file.src_path):
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 检查文章元数据是否禁用推荐
|
||||||
|
try:
|
||||||
|
with open(page.file.abs_src_path, 'r', encoding='utf-8') as f:
|
||||||
|
content = f.read()
|
||||||
|
metadata = extract_metadata(content)
|
||||||
|
if metadata.get('disable_related', False):
|
||||||
|
return markdown
|
||||||
|
except Exception:
|
||||||
|
pass # 如果读取失败,继续处理
|
||||||
|
|
||||||
|
# 获取相关文章
|
||||||
|
related_articles = get_related_articles(page.file.src_path, max_count=5)
|
||||||
|
|
||||||
|
if not related_articles:
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 从 config 中获取 site_url 并解析出基本路径
|
||||||
|
site_url = config.get('site_url', '')
|
||||||
|
base_path = urlparse(site_url).path if site_url else '/'
|
||||||
|
if not base_path.endswith('/'):
|
||||||
|
base_path += '/'
|
||||||
|
|
||||||
|
# 构建推荐HTML - 针对Safari浏览器优化
|
||||||
|
recommendation_html = "\n"
|
||||||
|
|
||||||
|
# 添加CSS样式,特别针对Safari浏览器优化
|
||||||
|
recommendation_html += """<style>
|
||||||
|
.related-posts {
|
||||||
|
margin-top: 1.5rem;
|
||||||
|
padding-top: 0.75rem;
|
||||||
|
border-top: 1px solid rgba(0,0,0,0.1);
|
||||||
|
max-height: none !important; /* 防止Safari错误计算高度 */
|
||||||
|
overflow: visible !important; /* 防止内容被截断 */
|
||||||
|
}
|
||||||
|
.related-posts h3 {
|
||||||
|
margin-top: 0;
|
||||||
|
margin-bottom: 0.5rem;
|
||||||
|
font-size: 1.2rem;
|
||||||
|
font-weight: 500;
|
||||||
|
line-height: 1.3;
|
||||||
|
}
|
||||||
|
.related-posts ul {
|
||||||
|
margin: 0 0 0.5rem 0 !important; /* 强制覆盖可能的冲突样式 */
|
||||||
|
padding-left: 1.5rem;
|
||||||
|
list-style-position: outside;
|
||||||
|
}
|
||||||
|
.related-posts li {
|
||||||
|
margin-bottom: 0.25rem;
|
||||||
|
line-height: 1.4;
|
||||||
|
}
|
||||||
|
/* 暗色模式适配 */
|
||||||
|
[data-md-color-scheme="slate"] .related-posts {
|
||||||
|
border-top-color: rgba(255,255,255,0.1);
|
||||||
|
}
|
||||||
|
/* Safari特定修复 */
|
||||||
|
@supports (-webkit-hyphens:none) {
|
||||||
|
.related-posts {
|
||||||
|
display: block;
|
||||||
|
position: relative;
|
||||||
|
height: auto !important;
|
||||||
|
}
|
||||||
|
.related-posts ul {
|
||||||
|
position: static;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
"""
|
||||||
|
|
||||||
|
# 简化且兼容的HTML结构
|
||||||
|
recommendation_html += '<div class="related-posts">\n'
|
||||||
|
recommendation_html += '<h3>📚 相关文章推荐</h3>\n'
|
||||||
|
recommendation_html += '<ul>\n'
|
||||||
|
|
||||||
|
for score, article_info in related_articles:
|
||||||
|
title = article_info['title']
|
||||||
|
relative_url = article_info['url']
|
||||||
|
# 拼接基本路径和文章相对URL,并确保路径分隔符正确
|
||||||
|
full_url = (base_path + relative_url).replace('//', '/')
|
||||||
|
recommendation_html += f'<li><a href="{full_url}">{title}</a></li>\n'
|
||||||
|
|
||||||
|
recommendation_html += '</ul>\n'
|
||||||
|
recommendation_html += '</div>\n'
|
||||||
|
|
||||||
|
# 确保没有多余的空行
|
||||||
|
return markdown.rstrip() + recommendation_html
|
||||||
|
|
||||||
|
def get_related_articles(current_path, max_count=5):
|
||||||
|
"""获取相关文章,使用改进的算法"""
|
||||||
|
if current_path not in article_index:
|
||||||
|
return []
|
||||||
|
|
||||||
|
current_article = article_index[current_path]
|
||||||
|
similarities = []
|
||||||
|
|
||||||
|
# 获取当前文章的关键信息
|
||||||
|
current_title = current_article['title'].lower()
|
||||||
|
current_tags = set(tag.lower() for tag in current_article['tags'] if tag)
|
||||||
|
current_categories = set(cat.lower() for cat in current_article['categories'] if cat)
|
||||||
|
|
||||||
|
for path, article_info in article_index.items():
|
||||||
|
if path == current_path:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 过滤掉标题为"未命名"的文章
|
||||||
|
if article_info['title'] == "未命名" or not article_info['title'].strip():
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 再次检查是否在排除列表中(双重检查)
|
||||||
|
if is_page_excluded(path):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 计算相似度
|
||||||
|
score = calculate_similarity(current_article, article_info)
|
||||||
|
|
||||||
|
# 标题相似度加权
|
||||||
|
title_similarity = calculate_title_similarity(current_title, article_info['title'].lower())
|
||||||
|
if title_similarity > 0.3: # 标题有一定相似度
|
||||||
|
score += title_similarity * SIMILARITY_CONFIG['title_similarity']
|
||||||
|
|
||||||
|
# 应用最低阈值
|
||||||
|
if score > SIMILARITY_CONFIG['min_threshold']:
|
||||||
|
similarities.append((score, article_info))
|
||||||
|
|
||||||
|
# 按相似度排序
|
||||||
|
similarities.sort(key=lambda x: x[0], reverse=True)
|
||||||
|
|
||||||
|
# 多样性优化:确保不同分类的文章都有机会被推荐
|
||||||
|
if len(similarities) > max_count * 2:
|
||||||
|
# 按分类分组
|
||||||
|
category_groups = defaultdict(list)
|
||||||
|
for score, article in similarities:
|
||||||
|
for category in article['categories']:
|
||||||
|
if category:
|
||||||
|
category_groups[category.lower()].append((score, article))
|
||||||
|
|
||||||
|
# 从每个分类中选取最相关的文章
|
||||||
|
diverse_results = []
|
||||||
|
used_paths = set()
|
||||||
|
|
||||||
|
# 首先添加最相关的文章
|
||||||
|
if similarities:
|
||||||
|
top_score, top_article = similarities[0]
|
||||||
|
diverse_results.append((top_score, top_article))
|
||||||
|
used_paths.add(top_article['path'])
|
||||||
|
|
||||||
|
# 然后从每个分类中添加最相关的文章
|
||||||
|
for category in sorted(category_groups.keys()):
|
||||||
|
if len(diverse_results) >= max_count:
|
||||||
|
break
|
||||||
|
|
||||||
|
for score, article in category_groups[category]:
|
||||||
|
if article['path'] not in used_paths:
|
||||||
|
diverse_results.append((score, article))
|
||||||
|
used_paths.add(article['path'])
|
||||||
|
break
|
||||||
|
|
||||||
|
# 如果还有空位,从剩余的高分文章中填充
|
||||||
|
if len(diverse_results) < max_count:
|
||||||
|
for score, article in similarities:
|
||||||
|
if article['path'] not in used_paths and len(diverse_results) < max_count:
|
||||||
|
diverse_results.append((score, article))
|
||||||
|
used_paths.add(article['path'])
|
||||||
|
|
||||||
|
# 重新按相似度排序
|
||||||
|
diverse_results.sort(key=lambda x: x[0], reverse=True)
|
||||||
|
return diverse_results[:max_count]
|
||||||
|
|
||||||
|
return similarities[:max_count]
|
||||||
|
|
||||||
|
def calculate_title_similarity(title1, title2):
|
||||||
|
"""计算两个标题的相似度"""
|
||||||
|
# 分词
|
||||||
|
words1 = set(re.findall(r'\b\w+\b', title1))
|
||||||
|
words2 = set(re.findall(r'\b\w+\b', title2))
|
||||||
|
|
||||||
|
if not words1 or not words2:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
# 计算Jaccard相似度
|
||||||
|
intersection = len(words1.intersection(words2))
|
||||||
|
union = len(words1.union(words2))
|
||||||
|
|
||||||
|
if union == 0:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
return intersection / union
|
||||||
|
|
||||||
|
def calculate_similarity(article1, article2):
|
||||||
|
"""计算两篇文章的相似度"""
|
||||||
|
score = 0
|
||||||
|
weights = SIMILARITY_CONFIG['weights']
|
||||||
|
|
||||||
|
# 1. 关键词相似度
|
||||||
|
keywords1 = dict(article1['keywords'])
|
||||||
|
keywords2 = dict(article2['keywords'])
|
||||||
|
common_keywords = set(keywords1.keys()) & set(keywords2.keys())
|
||||||
|
|
||||||
|
if common_keywords:
|
||||||
|
# 考虑关键词的频率和重要性
|
||||||
|
keyword_score = sum(min(keywords1[kw], keywords2[kw]) for kw in common_keywords)
|
||||||
|
# 关键词匹配数量的奖励
|
||||||
|
keyword_count_bonus = len(common_keywords) / max(len(keywords1), 1) * 0.5
|
||||||
|
score += (keyword_score + keyword_count_bonus) * weights['keywords']
|
||||||
|
|
||||||
|
# 2. 标签相似度
|
||||||
|
tags1 = set(tag.lower() for tag in article1['tags'] if tag)
|
||||||
|
tags2 = set(tag.lower() for tag in article2['tags'] if tag)
|
||||||
|
|
||||||
|
if tags1 and tags2: # 确保两篇文章都有标签
|
||||||
|
tag_overlap = len(tags1 & tags2)
|
||||||
|
tag_ratio = tag_overlap / max(len(tags1), 1) # 相对重叠比例
|
||||||
|
tag_score = tag_overlap * 8 * (1 + tag_ratio) # 增加重叠比例奖励
|
||||||
|
score += tag_score * weights['tags']
|
||||||
|
|
||||||
|
# 3. 分类相似度
|
||||||
|
categories1 = set(cat.lower() for cat in article1['categories'] if cat)
|
||||||
|
categories2 = set(cat.lower() for cat in article2['categories'] if cat)
|
||||||
|
|
||||||
|
if categories1 and categories2: # 确保两篇文章都有分类
|
||||||
|
category_overlap = len(categories1 & categories2)
|
||||||
|
category_ratio = category_overlap / max(len(categories1), 1)
|
||||||
|
category_score = category_overlap * 12 * (1 + category_ratio)
|
||||||
|
score += category_score * weights['categories']
|
||||||
|
|
||||||
|
# 4. 路径分类相似度
|
||||||
|
if article1['path_category'] == article2['path_category']:
|
||||||
|
score += 3 * weights['path']
|
||||||
|
|
||||||
|
# 5. 同源目录加分
|
||||||
|
if article1.get('source_dir') == article2.get('source_dir'):
|
||||||
|
score += 2 * weights['source_dir']
|
||||||
|
|
||||||
|
return score
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## 效果如下
|
||||||
@ -48,7 +48,7 @@ t.parentNode.insertBefore(e,t)}})();
|
|||||||
<img class="ava" src="https://s1.imagehub.cc/images/2025/06/03/526b59b6a2e478f2ffa1629320e3e2ce.png" />
|
<img class="ava" src="https://s1.imagehub.cc/images/2025/06/03/526b59b6a2e478f2ffa1629320e3e2ce.png" />
|
||||||
<div class="card-header">
|
<div class="card-header">
|
||||||
<div>
|
<div>
|
||||||
<a href="https://wcowin.work/Mkdocs-AI-Summary/MkDocs-AI-Summary/">MkDocs AI Summary</a>
|
<a href="https://wcowin.work/Mkdocs-AI-Summary-Plus/MkDocs-AI-Summary/">MkDocs AI Summary</a>
|
||||||
</div>
|
</div>
|
||||||
<div class="info">
|
<div class="info">
|
||||||
AI驱动的摘要生成
|
AI驱动的摘要生成
|
||||||
|
|||||||
BIN
docs/overrides/hooks/__pycache__/related_posts.cpython-311.pyc
Normal file
BIN
docs/overrides/hooks/__pycache__/related_posts.cpython-311.pyc
Normal file
Binary file not shown.
503
docs/overrides/hooks/related_posts.py
Normal file
503
docs/overrides/hooks/related_posts.py
Normal file
@ -0,0 +1,503 @@
|
|||||||
|
import os
|
||||||
|
import re
|
||||||
|
from collections import Counter, defaultdict
|
||||||
|
from textwrap import dedent
|
||||||
|
import hashlib
|
||||||
|
import yaml
|
||||||
|
from urllib.parse import urlparse
|
||||||
|
|
||||||
|
# 存储所有文章的信息和索引
|
||||||
|
article_index = {}
|
||||||
|
category_index = defaultdict(list)
|
||||||
|
keyword_index = defaultdict(set)
|
||||||
|
|
||||||
|
# 配置:需要索引的目录
|
||||||
|
INDEXED_DIRECTORIES = ['blog/', 'develop/']
|
||||||
|
|
||||||
|
# 配置:排除推荐的页面列表(支持精确匹配和模式匹配)
|
||||||
|
EXCLUDED_PAGES = {
|
||||||
|
# 精确路径匹配
|
||||||
|
'blog/index.md',
|
||||||
|
'develop/index.md',
|
||||||
|
# 可以添加更多排除的页面
|
||||||
|
# 'blog/special-page.md',
|
||||||
|
}
|
||||||
|
|
||||||
|
# 配置:排除推荐的页面模式(支持通配符)
|
||||||
|
EXCLUDED_PATTERNS = [
|
||||||
|
r'.*\/index\.md$', # 排除所有 index.md 文件
|
||||||
|
r'.*\/archive\.md$', # 排除所有 archive.md 文件
|
||||||
|
r'blog\/posts?\/.*', # 排除 blog/post/ 和 blog/posts/ 目录下的所有文章
|
||||||
|
# 可以添加更多模式
|
||||||
|
# r'blog\/draft\/.*', # 排除草稿目录
|
||||||
|
]
|
||||||
|
|
||||||
|
# 配置:相似度阈值和权重
|
||||||
|
SIMILARITY_CONFIG = {
|
||||||
|
'min_threshold': 0.15, # 提高最低相似度阈值
|
||||||
|
'weights': {
|
||||||
|
'keywords': 0.35, # 关键词权重
|
||||||
|
'tags': 0.30, # 标签权重
|
||||||
|
'categories': 0.20, # 分类权重
|
||||||
|
'path': 0.10, # 路径分类权重
|
||||||
|
'source_dir': 0.05 # 源目录权重
|
||||||
|
},
|
||||||
|
'title_similarity': 0.25 # 标题相似度权重
|
||||||
|
}
|
||||||
|
|
||||||
|
def is_page_excluded(file_path):
|
||||||
|
"""检查页面是否应该排除推荐"""
|
||||||
|
# 精确匹配检查
|
||||||
|
if file_path in EXCLUDED_PAGES:
|
||||||
|
return True
|
||||||
|
|
||||||
|
# 模式匹配检查
|
||||||
|
for pattern in EXCLUDED_PATTERNS:
|
||||||
|
if re.match(pattern, file_path):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def should_index_file(file_path):
|
||||||
|
"""检查文件是否应该被索引"""
|
||||||
|
if not file_path.endswith('.md'):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# 先检查是否被排除
|
||||||
|
if is_page_excluded(file_path):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# 检查是否在指定目录下
|
||||||
|
for directory in INDEXED_DIRECTORIES:
|
||||||
|
if file_path.startswith(directory):
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def extract_keywords(content, title):
|
||||||
|
"""提取文章中的关键词,改进算法"""
|
||||||
|
# 移除YAML front matter
|
||||||
|
content = re.sub(r'^---\s*\n.*?\n---\s*\n', '', content, flags=re.DOTALL | re.MULTILINE)
|
||||||
|
|
||||||
|
# 移除代码块
|
||||||
|
content = re.sub(r'```.*?```', '', content, flags=re.DOTALL)
|
||||||
|
# 移除HTML标签
|
||||||
|
content = re.sub(r'<.*?>', '', content)
|
||||||
|
# 移除链接
|
||||||
|
content = re.sub(r'\[.*?\]\(.*?\)', '', content)
|
||||||
|
# 移除标题标记
|
||||||
|
content = re.sub(r'^#+\s+', '', content, flags=re.MULTILINE)
|
||||||
|
|
||||||
|
# 合并标题和内容,标题权重更高
|
||||||
|
title_words = re.findall(r'\b\w+\b', title.lower()) * 4 # 增加标题权重
|
||||||
|
content_words = re.findall(r'\b\w+\b', content.lower())
|
||||||
|
all_words = title_words + content_words
|
||||||
|
|
||||||
|
# 扩展停用词列表(包含中英文)
|
||||||
|
stopwords = {
|
||||||
|
# 英文停用词
|
||||||
|
'the', 'a', 'an', 'in', 'on', 'at', 'to', 'for', 'of', 'and', 'or', 'is', 'are', 'was', 'were',
|
||||||
|
'be', 'been', 'have', 'has', 'had', 'do', 'does', 'did', 'will', 'would', 'could', 'should',
|
||||||
|
'this', 'that', 'these', 'those', 'with', 'from', 'by', 'as', 'can', 'but', 'not', 'if', 'it',
|
||||||
|
'they', 'them', 'their', 'you', 'your', 'we', 'our', 'my', 'me', 'i', 'he', 'she', 'him', 'her',
|
||||||
|
# 常见无意义词
|
||||||
|
'about', 'above', 'after', 'again', 'all', 'also', 'any', 'because', 'before', 'between',
|
||||||
|
'both', 'each', 'few', 'first', 'get', 'how', 'into', 'just', 'last', 'made', 'make', 'may',
|
||||||
|
'most', 'new', 'now', 'old', 'only', 'other', 'over', 'said', 'same', 'see', 'some', 'such',
|
||||||
|
'take', 'than', 'then', 'time', 'two', 'use', 'very', 'way', 'well', 'where', 'when', 'which',
|
||||||
|
'while', 'who', 'why', 'work', 'world', 'year', 'years',
|
||||||
|
# 中文停用词
|
||||||
|
'的', '了', '和', '是', '就', '都', '而', '及', '与', '这', '那', '有', '在', '中', '为', '对', '等',
|
||||||
|
'能', '会', '可以', '没有', '什么', '一个', '自己', '这个', '那个', '这些', '那些', '如果', '因为', '所以'
|
||||||
|
}
|
||||||
|
|
||||||
|
# 过滤单词:长度>=2,不在停用词中,不是纯数字
|
||||||
|
words = [w for w in all_words
|
||||||
|
if len(w) >= 2 and w not in stopwords and not w.isdigit()]
|
||||||
|
|
||||||
|
# 返回词频最高的15个词
|
||||||
|
return Counter(words).most_common(15)
|
||||||
|
|
||||||
|
def extract_metadata(content):
|
||||||
|
"""提取文章元数据,支持YAML front matter"""
|
||||||
|
metadata = {
|
||||||
|
'title': "未命名",
|
||||||
|
'description': "",
|
||||||
|
'tags': [],
|
||||||
|
'categories': [],
|
||||||
|
'disable_related': False # 新增:是否禁用相关推荐
|
||||||
|
}
|
||||||
|
|
||||||
|
# 尝试解析YAML front matter
|
||||||
|
yaml_match = re.match(r'^---\s*\n(.*?)\n---\s*\n', content, re.DOTALL)
|
||||||
|
if yaml_match:
|
||||||
|
try:
|
||||||
|
yaml_content = yaml_match.group(1)
|
||||||
|
yaml_data = yaml.safe_load(yaml_content)
|
||||||
|
if yaml_data:
|
||||||
|
metadata['title'] = str(yaml_data.get('title', '未命名')).strip('"\'')
|
||||||
|
metadata['description'] = str(yaml_data.get('description', '')).strip('"\'')
|
||||||
|
metadata['disable_related'] = yaml_data.get('disable_related', False)
|
||||||
|
|
||||||
|
# 处理tags
|
||||||
|
tags = yaml_data.get('tags', [])
|
||||||
|
if isinstance(tags, list):
|
||||||
|
metadata['tags'] = [str(tag).strip() for tag in tags]
|
||||||
|
elif isinstance(tags, str):
|
||||||
|
metadata['tags'] = [tag.strip() for tag in tags.split(',') if tag.strip()]
|
||||||
|
|
||||||
|
# 处理categories
|
||||||
|
categories = yaml_data.get('categories', [])
|
||||||
|
if isinstance(categories, list):
|
||||||
|
metadata['categories'] = [str(cat).strip() for cat in categories]
|
||||||
|
elif isinstance(categories, str):
|
||||||
|
metadata['categories'] = [cat.strip() for cat in categories.split(',') if cat.strip()]
|
||||||
|
except yaml.YAMLError:
|
||||||
|
pass # 如果YAML解析失败,使用默认值
|
||||||
|
|
||||||
|
# 如果YAML解析失败,回退到正则表达式
|
||||||
|
if metadata['title'] == "未命名":
|
||||||
|
title_match = re.search(r'^title:\s*(.+)$', content, re.MULTILINE)
|
||||||
|
if title_match:
|
||||||
|
metadata['title'] = title_match.group(1).strip('"\'')
|
||||||
|
|
||||||
|
return metadata
|
||||||
|
|
||||||
|
def get_category_from_path(file_path):
|
||||||
|
"""从文件路径提取分类"""
|
||||||
|
parts = file_path.split('/')
|
||||||
|
if len(parts) > 2:
|
||||||
|
return parts[1] # blog/category/file.md 或 develop/category/file.md格式
|
||||||
|
elif len(parts) > 1:
|
||||||
|
return parts[0] # blog 或 develop
|
||||||
|
return "未分类"
|
||||||
|
|
||||||
|
def calculate_content_hash(content):
|
||||||
|
"""计算内容哈希,用于检测内容变化"""
|
||||||
|
return hashlib.md5(content.encode('utf-8')).hexdigest()
|
||||||
|
|
||||||
|
def on_files(files, config):
|
||||||
|
"""预处理所有文章,建立索引"""
|
||||||
|
global article_index, category_index, keyword_index
|
||||||
|
|
||||||
|
# 清空索引
|
||||||
|
article_index.clear()
|
||||||
|
category_index.clear()
|
||||||
|
keyword_index.clear()
|
||||||
|
|
||||||
|
processed_count = 0
|
||||||
|
excluded_count = 0
|
||||||
|
|
||||||
|
for file in files:
|
||||||
|
if should_index_file(file.src_path):
|
||||||
|
try:
|
||||||
|
with open(file.abs_src_path, 'r', encoding='utf-8') as f:
|
||||||
|
content = f.read()
|
||||||
|
|
||||||
|
# 提取元数据
|
||||||
|
metadata = extract_metadata(content)
|
||||||
|
|
||||||
|
# 检查是否禁用相关推荐
|
||||||
|
if metadata.get('disable_related', False):
|
||||||
|
excluded_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 再次检查是否在排除列表中(双重检查)
|
||||||
|
if is_page_excluded(file.src_path):
|
||||||
|
excluded_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 提取关键词
|
||||||
|
keywords = extract_keywords(content, metadata['title'])
|
||||||
|
|
||||||
|
# 获取分类
|
||||||
|
path_category = get_category_from_path(file.src_path)
|
||||||
|
|
||||||
|
# 构建文章信息
|
||||||
|
article_info = {
|
||||||
|
'title': metadata['title'],
|
||||||
|
'description': metadata['description'],
|
||||||
|
'tags': metadata['tags'],
|
||||||
|
'categories': metadata['categories'],
|
||||||
|
'path_category': path_category,
|
||||||
|
'keywords': keywords,
|
||||||
|
'url': file.url,
|
||||||
|
'path': file.src_path,
|
||||||
|
'content_hash': calculate_content_hash(content),
|
||||||
|
'source_dir': file.src_path.split('/')[0] # blog 或 develop
|
||||||
|
}
|
||||||
|
|
||||||
|
# 添加到主索引
|
||||||
|
article_index[file.src_path] = article_info
|
||||||
|
|
||||||
|
# 添加到分类索引
|
||||||
|
category_index[path_category].append(file.src_path)
|
||||||
|
for category in metadata['categories']:
|
||||||
|
if category: # 确保分类不为空
|
||||||
|
category_index[category].append(file.src_path)
|
||||||
|
|
||||||
|
# 添加到关键词索引
|
||||||
|
for keyword, _ in keywords:
|
||||||
|
keyword_index[keyword].add(file.src_path)
|
||||||
|
for tag in metadata['tags']:
|
||||||
|
if tag: # 确保标签不为空
|
||||||
|
keyword_index[tag.lower()].add(file.src_path)
|
||||||
|
|
||||||
|
processed_count += 1
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"❌ 处理文件 {file.src_path} 时出错: {e}")
|
||||||
|
|
||||||
|
print(f"✅ 已索引 {processed_count} 篇文章 (blog + develop)")
|
||||||
|
if excluded_count > 0:
|
||||||
|
print(f"📝 排除 {excluded_count} 篇禁用推荐或在排除列表中的文章")
|
||||||
|
print(f"📊 分类数量: {len(category_index)}")
|
||||||
|
print(f"🔤 关键词数量: {len(keyword_index)}")
|
||||||
|
return files
|
||||||
|
|
||||||
|
def on_page_markdown(markdown, **kwargs):
|
||||||
|
"""为每篇文章添加相关推荐"""
|
||||||
|
page = kwargs['page']
|
||||||
|
config = kwargs['config']
|
||||||
|
|
||||||
|
# 检查是否应该处理这个页面
|
||||||
|
if not should_index_file(page.file.src_path):
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 检查是否被排除
|
||||||
|
if is_page_excluded(page.file.src_path):
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 检查文章元数据是否禁用推荐
|
||||||
|
try:
|
||||||
|
with open(page.file.abs_src_path, 'r', encoding='utf-8') as f:
|
||||||
|
content = f.read()
|
||||||
|
metadata = extract_metadata(content)
|
||||||
|
if metadata.get('disable_related', False):
|
||||||
|
return markdown
|
||||||
|
except Exception:
|
||||||
|
pass # 如果读取失败,继续处理
|
||||||
|
|
||||||
|
# 获取相关文章
|
||||||
|
related_articles = get_related_articles(page.file.src_path, max_count=5)
|
||||||
|
|
||||||
|
if not related_articles:
|
||||||
|
return markdown
|
||||||
|
|
||||||
|
# 从 config 中获取 site_url 并解析出基本路径
|
||||||
|
site_url = config.get('site_url', '')
|
||||||
|
base_path = urlparse(site_url).path if site_url else '/'
|
||||||
|
if not base_path.endswith('/'):
|
||||||
|
base_path += '/'
|
||||||
|
|
||||||
|
# 构建推荐HTML - 针对Safari浏览器优化
|
||||||
|
recommendation_html = "\n"
|
||||||
|
|
||||||
|
# 添加CSS样式,特别针对Safari浏览器优化
|
||||||
|
recommendation_html += """<style>
|
||||||
|
.related-posts {
|
||||||
|
margin-top: 1.5rem;
|
||||||
|
padding-top: 0.75rem;
|
||||||
|
border-top: 1px solid rgba(0,0,0,0.1);
|
||||||
|
max-height: none !important; /* 防止Safari错误计算高度 */
|
||||||
|
overflow: visible !important; /* 防止内容被截断 */
|
||||||
|
}
|
||||||
|
.related-posts h3 {
|
||||||
|
margin-top: 0;
|
||||||
|
margin-bottom: 0.5rem;
|
||||||
|
font-size: 1.2rem;
|
||||||
|
font-weight: 500;
|
||||||
|
line-height: 1.3;
|
||||||
|
}
|
||||||
|
.related-posts ul {
|
||||||
|
margin: 0 0 0.5rem 0 !important; /* 强制覆盖可能的冲突样式 */
|
||||||
|
padding-left: 1.5rem;
|
||||||
|
list-style-position: outside;
|
||||||
|
}
|
||||||
|
.related-posts li {
|
||||||
|
margin-bottom: 0.25rem;
|
||||||
|
line-height: 1.4;
|
||||||
|
}
|
||||||
|
/* 暗色模式适配 */
|
||||||
|
[data-md-color-scheme="slate"] .related-posts {
|
||||||
|
border-top-color: rgba(255,255,255,0.1);
|
||||||
|
}
|
||||||
|
/* Safari特定修复 */
|
||||||
|
@supports (-webkit-hyphens:none) {
|
||||||
|
.related-posts {
|
||||||
|
display: block;
|
||||||
|
position: relative;
|
||||||
|
height: auto !important;
|
||||||
|
}
|
||||||
|
.related-posts ul {
|
||||||
|
position: static;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
"""
|
||||||
|
|
||||||
|
# 简化且兼容的HTML结构
|
||||||
|
recommendation_html += '<div class="related-posts">\n'
|
||||||
|
recommendation_html += '<h3>📚 相关文章推荐</h3>\n'
|
||||||
|
recommendation_html += '<ul>\n'
|
||||||
|
|
||||||
|
for score, article_info in related_articles:
|
||||||
|
title = article_info['title']
|
||||||
|
relative_url = article_info['url']
|
||||||
|
# 拼接基本路径和文章相对URL,并确保路径分隔符正确
|
||||||
|
full_url = (base_path + relative_url).replace('//', '/')
|
||||||
|
recommendation_html += f'<li><a href="{full_url}">{title}</a></li>\n'
|
||||||
|
|
||||||
|
recommendation_html += '</ul>\n'
|
||||||
|
recommendation_html += '</div>\n'
|
||||||
|
|
||||||
|
# 确保没有多余的空行
|
||||||
|
return markdown.rstrip() + recommendation_html
|
||||||
|
|
||||||
|
def get_related_articles(current_path, max_count=5):
|
||||||
|
"""获取相关文章,使用改进的算法"""
|
||||||
|
if current_path not in article_index:
|
||||||
|
return []
|
||||||
|
|
||||||
|
current_article = article_index[current_path]
|
||||||
|
similarities = []
|
||||||
|
|
||||||
|
# 获取当前文章的关键信息
|
||||||
|
current_title = current_article['title'].lower()
|
||||||
|
current_tags = set(tag.lower() for tag in current_article['tags'] if tag)
|
||||||
|
current_categories = set(cat.lower() for cat in current_article['categories'] if cat)
|
||||||
|
|
||||||
|
for path, article_info in article_index.items():
|
||||||
|
if path == current_path:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 过滤掉标题为"未命名"的文章
|
||||||
|
if article_info['title'] == "未命名" or not article_info['title'].strip():
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 再次检查是否在排除列表中(双重检查)
|
||||||
|
if is_page_excluded(path):
|
||||||
|
continue
|
||||||
|
|
||||||
|
# 计算相似度
|
||||||
|
score = calculate_similarity(current_article, article_info)
|
||||||
|
|
||||||
|
# 标题相似度加权
|
||||||
|
title_similarity = calculate_title_similarity(current_title, article_info['title'].lower())
|
||||||
|
if title_similarity > 0.3: # 标题有一定相似度
|
||||||
|
score += title_similarity * SIMILARITY_CONFIG['title_similarity']
|
||||||
|
|
||||||
|
# 应用最低阈值
|
||||||
|
if score > SIMILARITY_CONFIG['min_threshold']:
|
||||||
|
similarities.append((score, article_info))
|
||||||
|
|
||||||
|
# 按相似度排序
|
||||||
|
similarities.sort(key=lambda x: x[0], reverse=True)
|
||||||
|
|
||||||
|
# 多样性优化:确保不同分类的文章都有机会被推荐
|
||||||
|
if len(similarities) > max_count * 2:
|
||||||
|
# 按分类分组
|
||||||
|
category_groups = defaultdict(list)
|
||||||
|
for score, article in similarities:
|
||||||
|
for category in article['categories']:
|
||||||
|
if category:
|
||||||
|
category_groups[category.lower()].append((score, article))
|
||||||
|
|
||||||
|
# 从每个分类中选取最相关的文章
|
||||||
|
diverse_results = []
|
||||||
|
used_paths = set()
|
||||||
|
|
||||||
|
# 首先添加最相关的文章
|
||||||
|
if similarities:
|
||||||
|
top_score, top_article = similarities[0]
|
||||||
|
diverse_results.append((top_score, top_article))
|
||||||
|
used_paths.add(top_article['path'])
|
||||||
|
|
||||||
|
# 然后从每个分类中添加最相关的文章
|
||||||
|
for category in sorted(category_groups.keys()):
|
||||||
|
if len(diverse_results) >= max_count:
|
||||||
|
break
|
||||||
|
|
||||||
|
for score, article in category_groups[category]:
|
||||||
|
if article['path'] not in used_paths:
|
||||||
|
diverse_results.append((score, article))
|
||||||
|
used_paths.add(article['path'])
|
||||||
|
break
|
||||||
|
|
||||||
|
# 如果还有空位,从剩余的高分文章中填充
|
||||||
|
if len(diverse_results) < max_count:
|
||||||
|
for score, article in similarities:
|
||||||
|
if article['path'] not in used_paths and len(diverse_results) < max_count:
|
||||||
|
diverse_results.append((score, article))
|
||||||
|
used_paths.add(article['path'])
|
||||||
|
|
||||||
|
# 重新按相似度排序
|
||||||
|
diverse_results.sort(key=lambda x: x[0], reverse=True)
|
||||||
|
return diverse_results[:max_count]
|
||||||
|
|
||||||
|
return similarities[:max_count]
|
||||||
|
|
||||||
|
def calculate_title_similarity(title1, title2):
|
||||||
|
"""计算两个标题的相似度"""
|
||||||
|
# 分词
|
||||||
|
words1 = set(re.findall(r'\b\w+\b', title1))
|
||||||
|
words2 = set(re.findall(r'\b\w+\b', title2))
|
||||||
|
|
||||||
|
if not words1 or not words2:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
# 计算Jaccard相似度
|
||||||
|
intersection = len(words1.intersection(words2))
|
||||||
|
union = len(words1.union(words2))
|
||||||
|
|
||||||
|
if union == 0:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
return intersection / union
|
||||||
|
|
||||||
|
def calculate_similarity(article1, article2):
|
||||||
|
"""计算两篇文章的相似度"""
|
||||||
|
score = 0
|
||||||
|
weights = SIMILARITY_CONFIG['weights']
|
||||||
|
|
||||||
|
# 1. 关键词相似度
|
||||||
|
keywords1 = dict(article1['keywords'])
|
||||||
|
keywords2 = dict(article2['keywords'])
|
||||||
|
common_keywords = set(keywords1.keys()) & set(keywords2.keys())
|
||||||
|
|
||||||
|
if common_keywords:
|
||||||
|
# 考虑关键词的频率和重要性
|
||||||
|
keyword_score = sum(min(keywords1[kw], keywords2[kw]) for kw in common_keywords)
|
||||||
|
# 关键词匹配数量的奖励
|
||||||
|
keyword_count_bonus = len(common_keywords) / max(len(keywords1), 1) * 0.5
|
||||||
|
score += (keyword_score + keyword_count_bonus) * weights['keywords']
|
||||||
|
|
||||||
|
# 2. 标签相似度
|
||||||
|
tags1 = set(tag.lower() for tag in article1['tags'] if tag)
|
||||||
|
tags2 = set(tag.lower() for tag in article2['tags'] if tag)
|
||||||
|
|
||||||
|
if tags1 and tags2: # 确保两篇文章都有标签
|
||||||
|
tag_overlap = len(tags1 & tags2)
|
||||||
|
tag_ratio = tag_overlap / max(len(tags1), 1) # 相对重叠比例
|
||||||
|
tag_score = tag_overlap * 8 * (1 + tag_ratio) # 增加重叠比例奖励
|
||||||
|
score += tag_score * weights['tags']
|
||||||
|
|
||||||
|
# 3. 分类相似度
|
||||||
|
categories1 = set(cat.lower() for cat in article1['categories'] if cat)
|
||||||
|
categories2 = set(cat.lower() for cat in article2['categories'] if cat)
|
||||||
|
|
||||||
|
if categories1 and categories2: # 确保两篇文章都有分类
|
||||||
|
category_overlap = len(categories1 & categories2)
|
||||||
|
category_ratio = category_overlap / max(len(categories1), 1)
|
||||||
|
category_score = category_overlap * 12 * (1 + category_ratio)
|
||||||
|
score += category_score * weights['categories']
|
||||||
|
|
||||||
|
# 4. 路径分类相似度
|
||||||
|
if article1['path_category'] == article2['path_category']:
|
||||||
|
score += 3 * weights['path']
|
||||||
|
|
||||||
|
# 5. 同源目录加分
|
||||||
|
if article1.get('source_dir') == article2.get('source_dir'):
|
||||||
|
score += 2 * weights['source_dir']
|
||||||
|
|
||||||
|
return score
|
||||||
@ -15,7 +15,7 @@ button.md-top {
|
|||||||
font-family: LXGW WenKai; /* 修改字体 */
|
font-family: LXGW WenKai; /* 修改字体 */
|
||||||
font-size: 16px; /* 修改字体大小 */
|
font-size: 16px; /* 修改字体大小 */
|
||||||
font-weight: lighter;/* 修改字体粗细 */
|
font-weight: lighter;/* 修改字体粗细 */
|
||||||
color: #1D2636; /* 修改字体颜色 */
|
/* color: #1D2636; 修改字体颜色 */
|
||||||
}
|
}
|
||||||
|
|
||||||
:root {
|
:root {
|
||||||
@ -604,3 +604,27 @@ filter: progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);
|
|||||||
height: 30rem;
|
height: 30rem;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/* 仅针对文本链接设置红色 */
|
||||||
|
.md-typeset p a:not(.md-button):not([class*="md-"]):not([style*="background"]),
|
||||||
|
.md-typeset li a:not(.md-button):not([class*="md-"]):not([style*="background"]),
|
||||||
|
.md-typeset td a:not(.md-button):not([class*="md-"]):not([style*="background"]),
|
||||||
|
.md-typeset blockquote a:not(.md-button):not([class*="md-"]):not([style*="background"]) {
|
||||||
|
color: #5688F7 !important; /* 红色文本链接 */
|
||||||
|
text-decoration: none;
|
||||||
|
}
|
||||||
|
|
||||||
|
.md-typeset p a:not(.md-button):not([class*="md-"]):not([style*="background"]):hover,
|
||||||
|
.md-typeset li a:not(.md-button):not([class*="md-"]):not([style*="background"]):hover,
|
||||||
|
.md-typeset td a:not(.md-button):not([class*="md-"]):not([style*="background"]):hover,
|
||||||
|
.md-typeset blockquote a:not(.md-button):not([class*="md-"]):not([style*="background"]):hover {
|
||||||
|
color: #43d2e8 !important; /* 悬停时深红色 */
|
||||||
|
text-decoration: underline;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* 访问过的文本链接 */
|
||||||
|
/* .md-typeset p a:not(.md-button):not([class*="md-"]):not([style*="background"]):visited,
|
||||||
|
.md-typeset li a:not(.md-button):not([class*="md-"]):not([style*="background"]):visited,
|
||||||
|
.md-typeset td a:not(.md-button):not([class*="md-"]):not([style*="background"]):visited,
|
||||||
|
.md-typeset blockquote a:not(.md-button):not([class*="md-"]):not([style*="background"]):visited {
|
||||||
|
color: #b83280 !important;
|
||||||
|
} */
|
||||||
@ -41,3 +41,8 @@
|
|||||||
border-radius: 4px;
|
border-radius: 4px;
|
||||||
cursor: pointer;
|
cursor: pointer;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
/* 目录导航的缩进参考线 */
|
||||||
|
nav.md-nav--secondary ul {
|
||||||
|
border-left: 1px solid lightblue;
|
||||||
|
}
|
||||||
@ -76,6 +76,7 @@ nav:
|
|||||||
- 3.解决Github Pages部署mkdocs自定义域名失效的问题: blog/Mkdocs/mkdocs3.md
|
- 3.解决Github Pages部署mkdocs自定义域名失效的问题: blog/Mkdocs/mkdocs3.md
|
||||||
- Mkdocs美化/补充:
|
- Mkdocs美化/补充:
|
||||||
- MkDocs文档AI摘要: blog/websitebeauty/Mkdocs-AI-Summary.md
|
- MkDocs文档AI摘要: blog/websitebeauty/Mkdocs-AI-Summary.md
|
||||||
|
- 添加相关推荐文章: blog/websitebeauty/recommend.md
|
||||||
- 添加阅读信息统计: blog/websitebeauty/reading_time.md
|
- 添加阅读信息统计: blog/websitebeauty/reading_time.md
|
||||||
- 添加Mkdocs博客: blog/Mkdocs/mkdocsblog.md
|
- 添加Mkdocs博客: blog/Mkdocs/mkdocsblog.md
|
||||||
- 如何给MKdocs添加友链: blog/Mkdocs/linktech.md
|
- 如何给MKdocs添加友链: blog/Mkdocs/linktech.md
|
||||||
@ -319,3 +320,4 @@ hooks:
|
|||||||
- docs/overrides/hooks/socialmedia.py
|
- docs/overrides/hooks/socialmedia.py
|
||||||
- docs/overrides/hooks/reading_time.py
|
- docs/overrides/hooks/reading_time.py
|
||||||
- docs/overrides/hooks/ai_summary.py
|
- docs/overrides/hooks/ai_summary.py
|
||||||
|
- docs/overrides/hooks/related_posts.py
|
||||||
55
快速开始.md
55
快速开始.md
@ -1,16 +1,6 @@
|
|||||||
---
|
|
||||||
title: 利用Mkdocs部署静态网页至GitHubpages
|
|
||||||
tags:
|
|
||||||
- Mkdocs
|
|
||||||
---
|
|
||||||
|
|
||||||
!!! info
|
|
||||||
Material for MkDocs官方网站: [Material for MkDocs](https://www.mkdocs.org/)
|
|
||||||
MkDocs中文文档: [MkDocs中文文档](https://hellowac.github.io/mkdocs-docs-zh/)
|
|
||||||
---
|
|
||||||
推荐看下这个视频:
|
推荐看下这个视频:
|
||||||
:fontawesome-brands-bilibili:{ style="color: #EE98A7" }
|
|
||||||
__[How to set up Material for MkDocs]__ by @Wcowin – :octicons-clock-24:
|
__[How to set up Material for MkDocs]__ by @Wcowin –
|
||||||
10m – 用MKdocs构建一个博客网站.
|
10m – 用MKdocs构建一个博客网站.
|
||||||
|
|
||||||
[How to set up Material for MkDocs]: https://space.bilibili.com/1407028951/lists/4566631?type=series
|
[How to set up Material for MkDocs]: https://space.bilibili.com/1407028951/lists/4566631?type=series
|
||||||
@ -61,42 +51,6 @@ mkdocs new mkdocs-site
|
|||||||
|
|
||||||
执行下面的代码添加一个GitHub Workflow
|
执行下面的代码添加一个GitHub Workflow
|
||||||
***
|
***
|
||||||
???note "过时的PublishMySite.yml"
|
|
||||||
(执行下面的代码添加一个GitHub Workflow(**已经过时但是仍然能用,最新方法见下方ci.yml**)
|
|
||||||
|
|
||||||
```
|
|
||||||
mkdir .github
|
|
||||||
cd .github
|
|
||||||
mkdir workflows
|
|
||||||
cd workflows
|
|
||||||
vim PublishMySite.yml
|
|
||||||
```
|
|
||||||
|
|
||||||
在PublishMySite.yml里面输入以下内容
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
name: publish site
|
|
||||||
on: # 在什么时候触发工作流
|
|
||||||
push: # 在从本地main分支被push到GitHub仓库时
|
|
||||||
branches:
|
|
||||||
- main
|
|
||||||
pull_request: # 在main分支合并别人提的pr时
|
|
||||||
branches:
|
|
||||||
- main
|
|
||||||
jobs: # 工作流的具体内容
|
|
||||||
deploy:
|
|
||||||
runs-on: ubuntu-latest # 创建一个新的云端虚拟机 使用最新Ubuntu系统
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v2 # 先checkout到main分支
|
|
||||||
- uses: actions/setup-python@v2 # 再安装Python3和相关环境
|
|
||||||
with:
|
|
||||||
python-version: 3.x
|
|
||||||
- run: pip install mkdocs-material # 使用pip包管理工具安装mkdocs-material
|
|
||||||
- run: mkdocs gh-deploy --force # 使用mkdocs-material部署gh-pages分支
|
|
||||||
|
|
||||||
```
|
|
||||||
)
|
|
||||||
***
|
|
||||||
|
|
||||||
```
|
```
|
||||||
mkdir .github
|
mkdir .github
|
||||||
@ -155,8 +109,7 @@ Wcowin.github.io
|
|||||||
└── mkdocs.yml
|
└── mkdocs.yml
|
||||||
```
|
```
|
||||||
|
|
||||||
|
**重点来了**
|
||||||
!!!重点来了
|
|
||||||
Github仓库setings/Actions/General 勾选这两项
|
Github仓库setings/Actions/General 勾选这两项
|
||||||
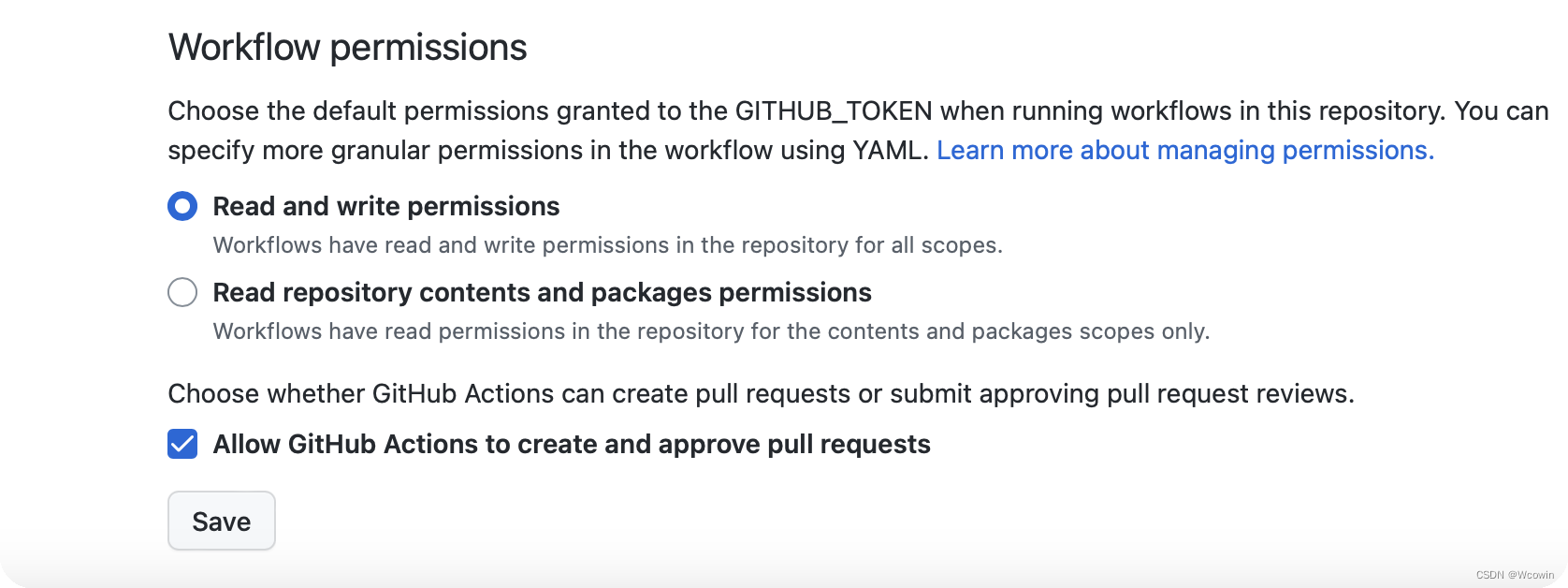
|

|
||||||
|
|
||||||
@ -177,7 +130,7 @@ theme:
|
|||||||
|
|
||||||
详细mkdocs.yml配置见[Changing the colors - Material for MkDocs](https://squidfunk.github.io/mkdocs-material/setup/changing-the-colors/)
|
详细mkdocs.yml配置见[Changing the colors - Material for MkDocs](https://squidfunk.github.io/mkdocs-material/setup/changing-the-colors/)
|
||||||
|
|
||||||
[下次](https://blog.csdn.net/m0_63203517/article/details/127444446?spm=1001.2014.3001.5502)我会具体谈谈这个问题
|
|
||||||
***
|
***
|
||||||
在下方终端运行可以在浏览器看到实时网站
|
在下方终端运行可以在浏览器看到实时网站
|
||||||
```
|
```
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user